
Google has introduced Gemma 4, an open model family designed for advanced reasoning and agentic workflows. The models are built to deliver high intelligence-per-parameter while remaining efficient across a wide range of hardware environments. Gemma 4 is positioned as part of Google’s broader AI ecosystem and complements its proprietary Gemini models.
The release follows strong adoption of earlier Gemma models, which have recorded over 400 million downloads and contributed to a large community-driven ecosystem with more than 100,000 variants. Gemma 4 continues this direction by making its capabilities available under a commercially permissive Apache 2.0 license.
Gemma 4 open AI models
Gemma 4 is available in four variants designed for different compute and deployment needs:
- Effective 2B (E2B)
- Effective 4B (E4B)
- 26B Mixture of Experts (MoE)
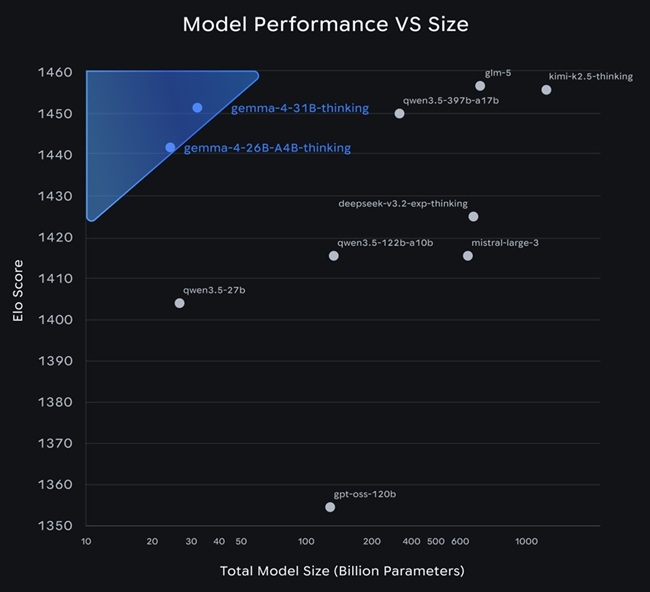
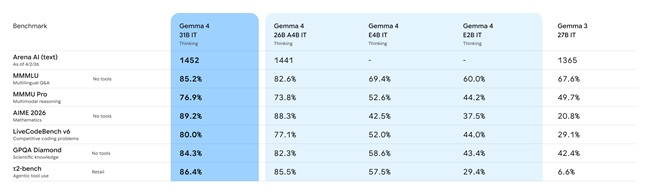
- 31B Dense
The 26B MoE model activates a subset of parameters during inference (around 3.8 billion active parameters), improving efficiency and latency. The 31B dense model uses all parameters and is designed to prioritize output quality and serve as a strong base for fine-tuning.
The larger models are intended for high-performance hardware, including workstation GPUs and accelerator environments, while the smaller E2B and E4B models are optimized for edge devices such as smartphones and embedded systems.
Key features
- Advanced reasoning: Supports multi-step logic, planning, and improved performance on math and instruction-following tasks.
- Agentic workflows: Includes native function calling, structured JSON outputs, and system instruction support for building tool-using AI agents.
- Multimodal inputs: Processes images and video natively, supporting OCR, chart understanding, and visual analysis. E2B and E4B also support audio input for speech-related tasks.
- Long context windows: Up to 128K tokens for edge models and up to 256K tokens for larger models, enabling handling of long documents and codebases.
- Code generation: Supports offline code generation for development workflows and local AI-assisted coding.
- Multilingual coverage: Trained across more than 140 languages for global use cases.
- Hardware efficiency: Optimized to run across GPUs, mobile devices, and edge hardware with efficient compute and memory usage.
- Edge deployment: E2B and E4B models run fully offline with low latency on devices such as smartphones and embedded platforms.
- Research and applied use cases: Used in projects such as BgGPT by INSAIT and Cell2Sentence-Scale research at Yale University for scientific exploration.
Open-source licensing
Gemma 4 is released under the Apache 2.0 license, which allows commercial and non-commercial use with minimal restrictions. Developers can modify, fine-tune, and deploy the models while maintaining control over data, infrastructure, and deployment environments.
The license supports flexible usage across on-premises systems, private infrastructure, and cloud platforms without restrictive licensing constraints.
Ecosystem and tooling support
Gemma 4 is supported across a wide range of AI frameworks and developer tools, enabling integration into different workflows and deployment setups.
Supported tools include Hugging Face (Transformers, TRL, Transformers.js, Candle), vLLM, llama.cpp, Ollama, NVIDIA NIM and NeMo, LM Studio, Unsloth, SGLang, Docker, MaxText, Tunix, and Keras.
Model access and experimentation options include:
- Google AI Studio for larger models
- Google AI Edge Gallery for edge-optimized models
- Hugging Face, Kaggle, and Ollama for downloads
Deployment options include:
- Local inference on consumer GPUs and developer systems
- Edge deployment on mobile and embedded devices
- Cloud deployment via Google Cloud services such as Vertex AI, Cloud Run, GKE, and Sovereign Cloud
- TPU-based serving for large-scale workloads
The models are compatible with multiple hardware ecosystems, including NVIDIA GPUs, AMD GPUs via ROCm, and Google TPUs.
Safety
Gemma 4 follows established security and safety practices aligned with Google’s internal model development standards. These include infrastructure-level protections, reliability checks, and controlled deployment practices.
The models are designed to meet enterprise and regulated requirements, providing a stable and transparent foundation for production use while maintaining consistent performance.
Availability
Gemma 4 is available through multiple platforms for experimentation, development, and deployment:
- Google AI Studio for accessing 26B MoE and 31B models
- Google AI Edge Gallery for E2B and E4B models
- Android development tools such as Android Studio with Agent Mode and ML Kit GenAI Prompt API
- Model weights distributed via Hugging Face, Kaggle, and Ollama
Developers can run Gemma 4 locally, fine-tune it for specific tasks, or deploy it at scale using cloud infrastructure. The models are supported across local, edge, and cloud environments, enabling flexible workflows from prototyping to production deployments.