
Microsoft has announced three new AI models—MAI-Transcribe-1, MAI-Voice-1, and MAI-Image-2—in public preview through its AI development platform Microsoft Foundry.
The update is part of Microsoft’s broader approach to building a unified AI and application agent platform that provides developers with access to models, infrastructure, and tools for building scalable AI systems.
The same models are already used across Microsoft products such as Copilot, Bing, PowerPoint, and Azure Speech, and are now available for developers exclusively through Foundry.
MAI Model Family
The MAI model family consists of three multimodal AI models designed to support speech, voice, and image workflows:
- MAI-Transcribe-1: Speech recognition model for converting audio to text
- MAI-Voice-1: Speech generation model for converting text to audio
- MAI-Image-2: Text-to-image generation model for creating visuals from prompts
Together, these models form a first-party AI stack that enables developers to build applications involving real-time transcription, voice interactions, and image generation within a single ecosystem. All three models are available in public preview via Microsoft Foundry.
![]()
MAI-Transcribe-1
MAI-Transcribe-1 is a speech recognition model designed for enterprise transcription workloads. It supports up to 25 languages and is built to handle varied accents and real-world audio conditions.
The model delivers competitive transcription accuracy while reducing computational requirements, achieving approximately 50% lower GPU cost compared to leading alternatives when benchmarked. This efficiency supports scalable deployment across large systems with predictable cost behavior.
It is suitable for applications such as real-time transcription, call center analytics, voice input systems, and audio processing pipelines. The model is also used internally in Microsoft’s Copilot features, including voice mode and dictation capabilities.
MAI-Voice-1
MAI-Voice-1 is a speech synthesis model focused on producing natural and expressive audio with low latency. It can generate up to 60 seconds of audio in under one second on a single GPU, enabling fast response times in voice-based applications.
The model supports a wide range of use cases including conversational agents, voice assistants, and audio content generation. It produces speech output that is designed to sound natural and expressive across different scenarios.
MAI-Voice-1 is integrated into Microsoft’s ecosystem, supporting features such as Copilot audio experiences and podcast-style outputs. Developers can also use Azure Speech’s Personal Voice feature to create custom voices from short audio samples, subject to a responsible AI approval process.
MAI-Image-2
MAI-Image-2 is Microsoft’s text-to-image generation model designed for creating high-quality visuals from text prompts. It focuses on photorealistic outputs, improved text rendering within images, and better handling of complex layouts and scenes.
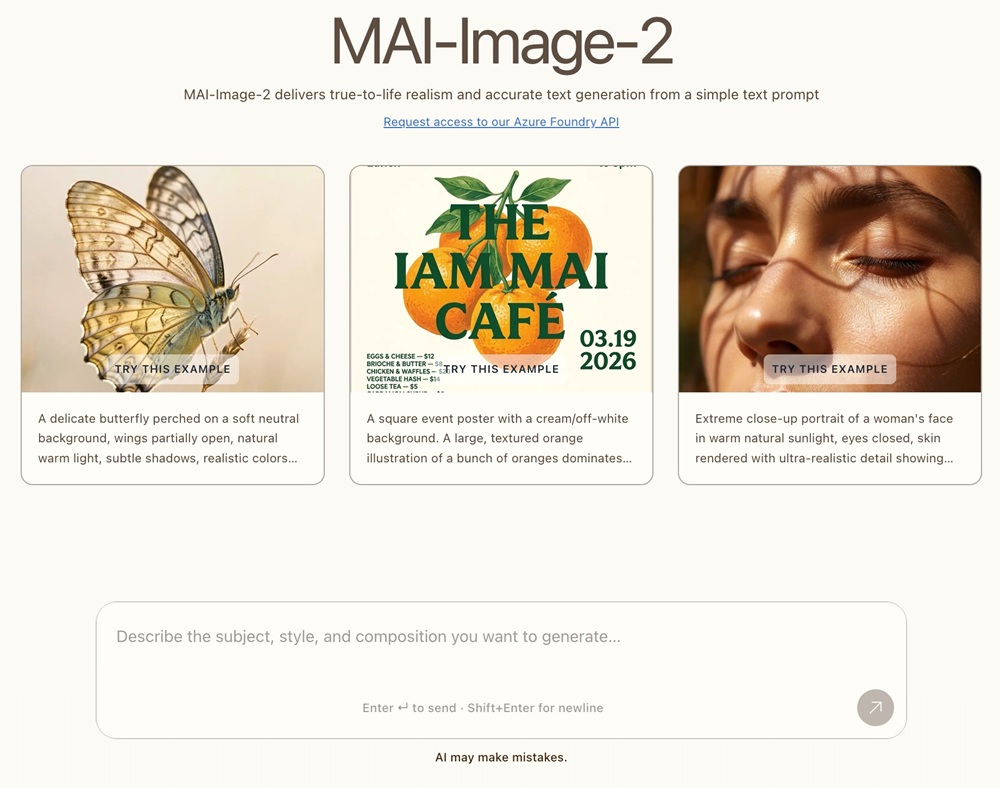
The model has been trained with input from designers, photographers, and visual storytellers. It debuted at #3 on the Arena.ai leaderboard for image model families, indicating strong performance among comparable systems.
MAI-Image-2 can generate detailed and structured visuals suitable for design concepts, marketing materials, product visualization, and internal communications. It is also used within Microsoft products such as Copilot, Bing Image Creator, and PowerPoint, and is adopted by enterprise partners including WPP for creative workflows.
Pricing and Availability
The MAI models are available in public preview through Microsoft Foundry and are exclusively accessible to developers via Foundry, with additional integration available through Azure Speech for voice-related capabilities.
Access methods:
- MAI Playground for testing and experimentation
- Foundry APIs for application and agent development
- Azure Speech for deployment of voice models
Pricing:
- MAI-Transcribe-1: $0.36 per hour
- MAI-Voice-1: $22 per 1M characters
- MAI-Image-2:
- $5 per 1M tokens (text input)
- $33 per 1M tokens (image output)
Developers can begin experimenting in the Playground and deploy these models into production environments through Foundry while following Microsoft’s responsible AI guidelines for features such as voice cloning.