
OpenAI has released GPT‑5.4 in ChatGPT (as GPT‑5.4 Thinking), the API, and Codex, marking its most capable and efficient frontier model for professional work. The company also introduced GPT‑5.4 Pro for users seeking maximum performance on complex tasks.
GPT‑5.4 Overview
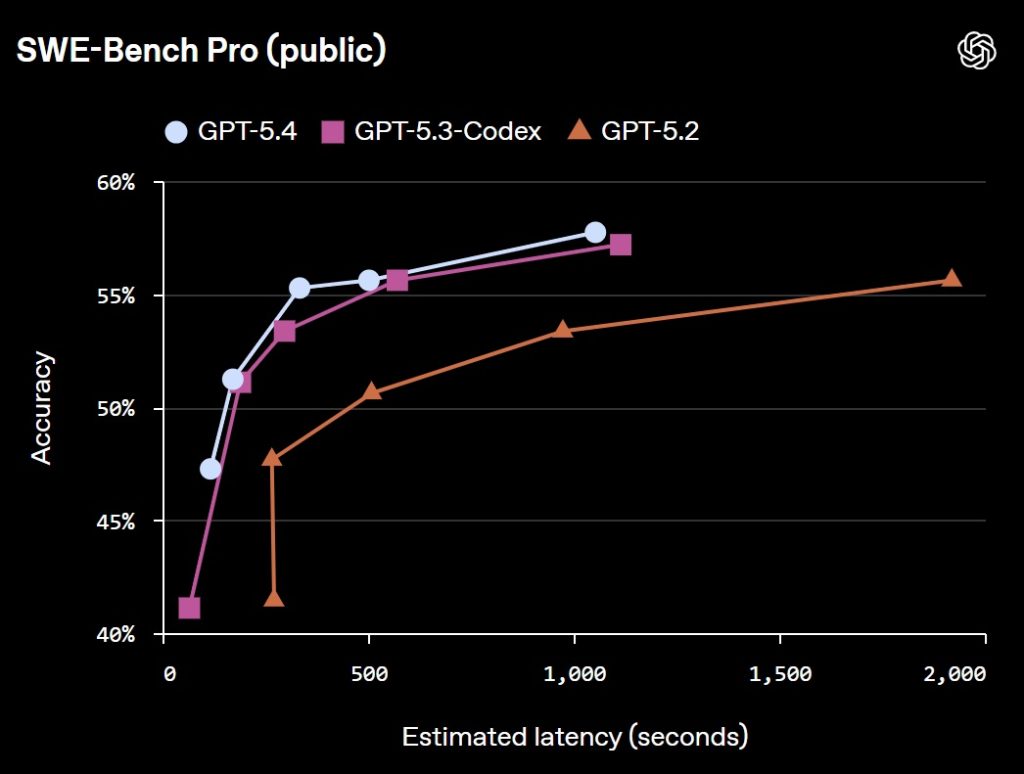
GPT‑5.4 combines advances in reasoning, coding, and agentic workflows into a single frontier model. It incorporates the coding capabilities of GPT‑5.3‑Codex while improving performance across tools, software environments, and professional tasks such as spreadsheets, presentations, and documents.
In ChatGPT, GPT‑5.4 Thinking provides an upfront reasoning plan, lets users adjust course mid-response, and maintains context for longer or more complex queries. This results in faster, more accurate, and higher-quality answers.

In Codex and the API, GPT‑5.4 introduces native computer-use capabilities, enabling agents to operate computers and execute complex workflows across applications. It supports up to 1 million tokens of context, includes tool search for efficient management of large tool ecosystems, and is the most token-efficient reasoning model to date, using fewer tokens than GPT‑5.2 while delivering faster outputs.
Key Features
Knowledge Work
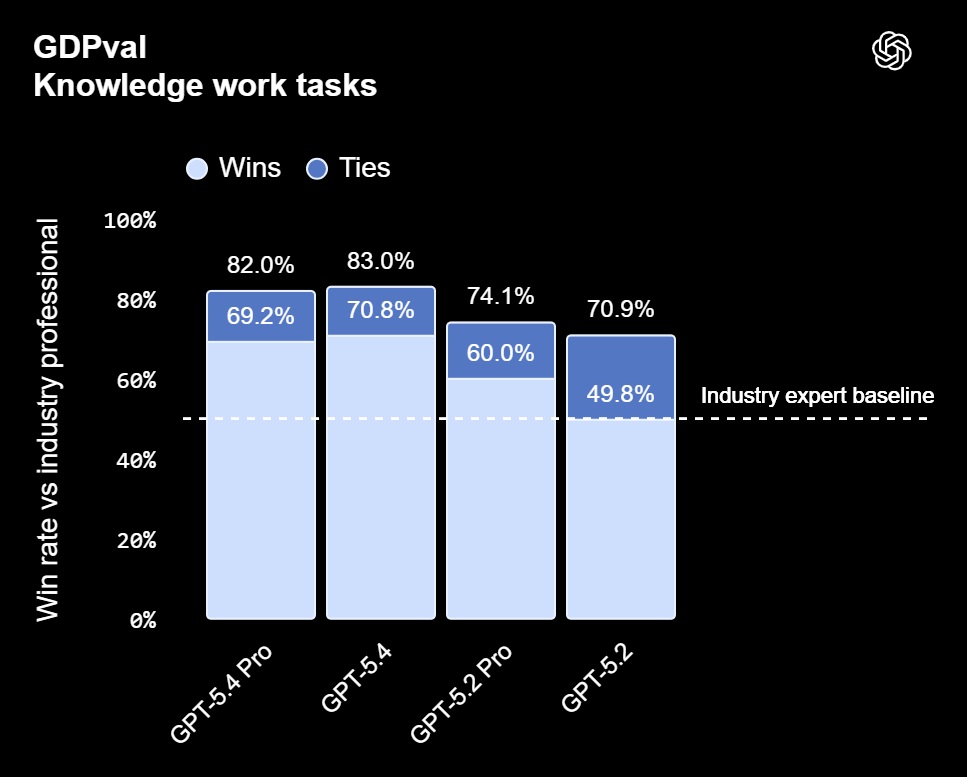
- GDPval benchmark: matches or exceeds professionals in 83.0% of comparisons (GPT‑5.2: 70.9%).
- Spreadsheet modeling tasks: achieves 87.3% accuracy vs. 68.4% for GPT‑5.2.
- Presentation evaluation: preferred 68% of the time over GPT‑5.2 outputs.
- Reduced errors: 33% fewer false claims; 18% fewer responses with any errors.
- Updated Excel add-in, spreadsheet, and presentation skills available in ChatGPT, Codex, and API.
Computer Use & Vision
- Native computer-use: writes code to operate computers (e.g., Playwright), issues mouse/keyboard commands, and supports multi-step workflows.
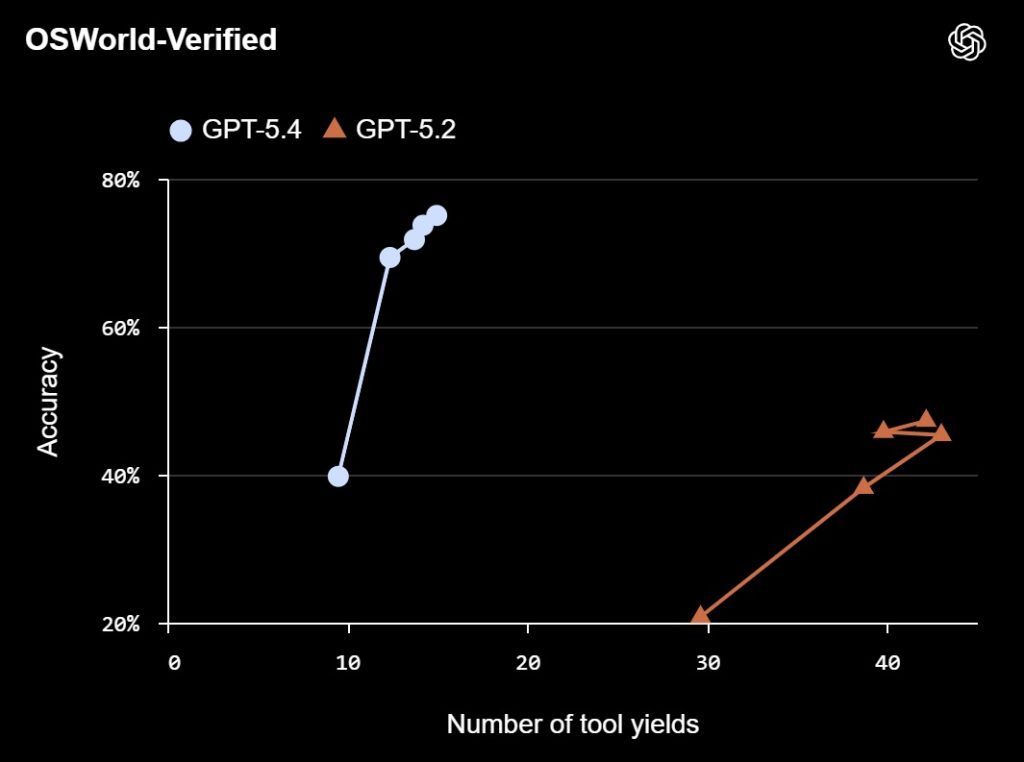
- Desktop benchmarks: OSWorld-Verified success 75.0% (GPT‑5.2: 47.3%; human: 72.4%).
- Browser benchmarks: WebArena-Verified success 67.3%; Online-Mind2Web screenshot success 92.8% (ChatGPT Atlas: 70.9%).
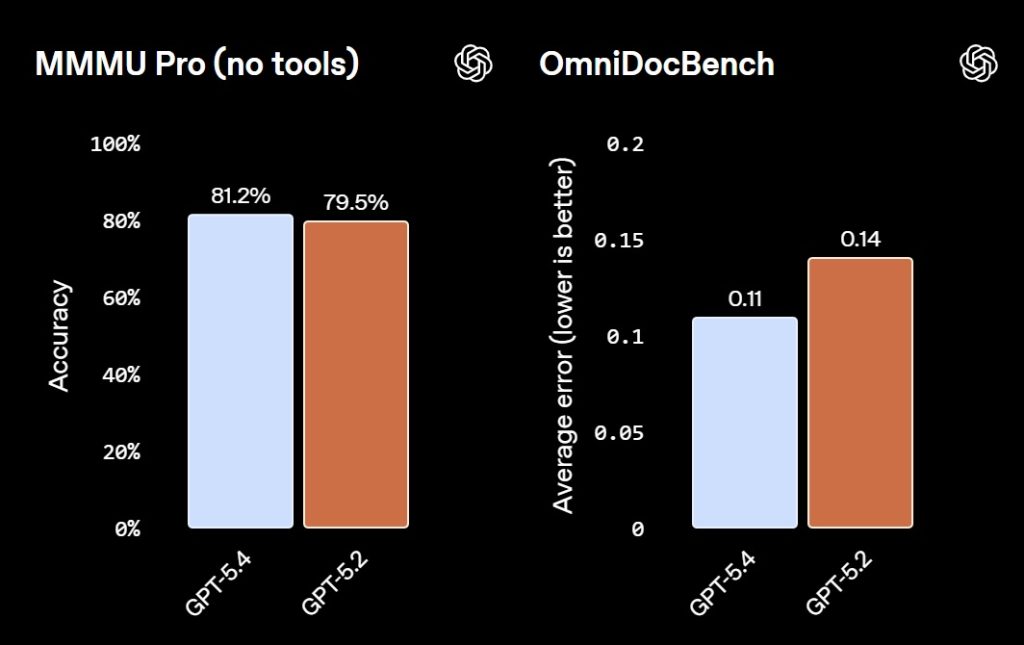
- Visual perception: MMMU-Pro success 81.2% vs. 79.5% for GPT‑5.2.
- Document parsing: OmniDocBench error reduced from 0.140 → 0.109.
- High-resolution images: supports up to 10.24M pixels (original), high detail up to 2.56M pixels.
Coding
- Combines GPT‑5.3‑Codex coding capabilities with reasoning and tool workflows.
/fast modedelivers up to 1.5× faster token velocity.- Excels at complex frontend tasks with more functional and aesthetic outputs.
- Experimental Playwright (Interactive) skill enables visual debugging of web and Electron apps.
Tool Use & Agentic Workflows
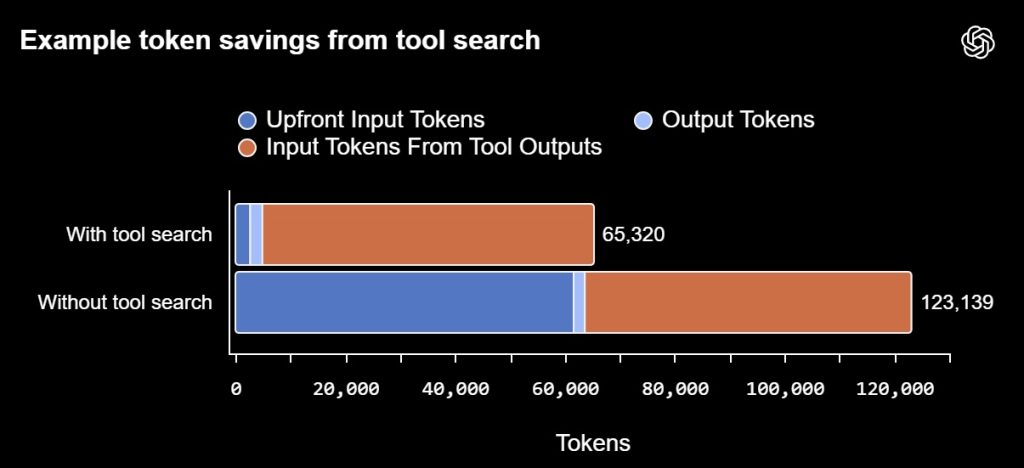
- Tool search: reduces token usage by 47% for large tool ecosystems.
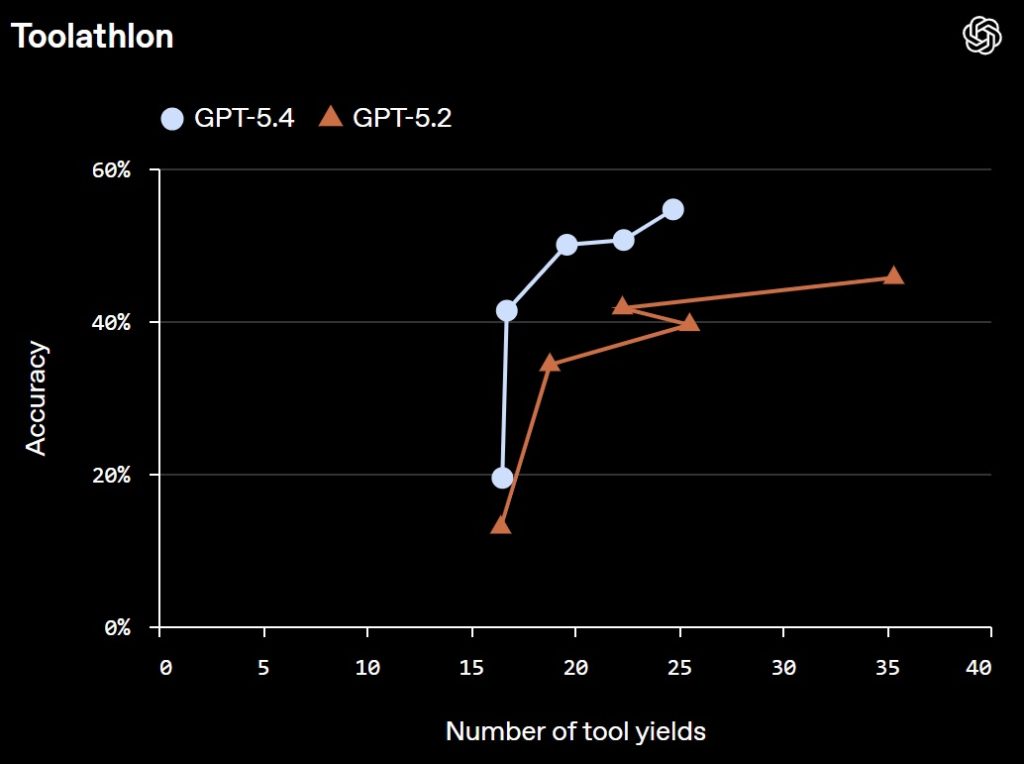
- Agentic tool calling: higher accuracy and fewer turns on multi-step tasks (Toolathlon benchmark).
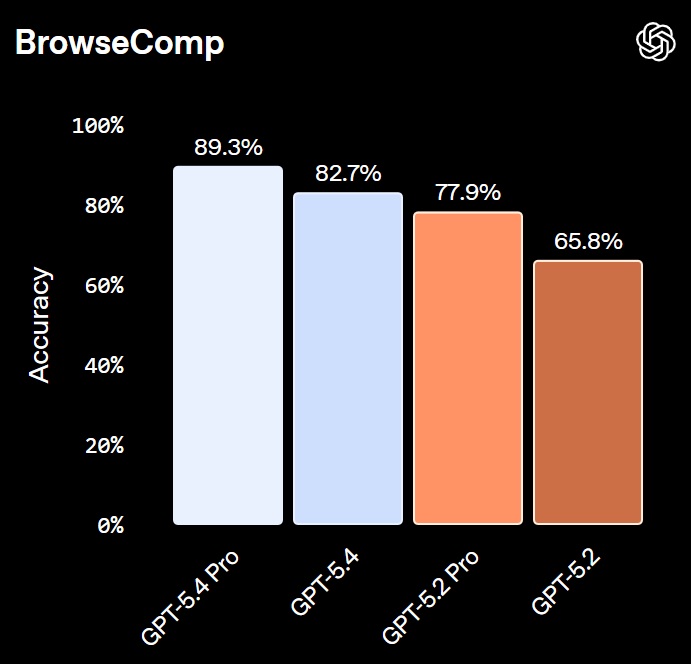
- Improved web search: BrowseComp success up 17% vs. GPT‑5.2; GPT‑5.4 Pro achieves 89.3%.
- Steerability: GPT‑5.4 Thinking outlines reasoning steps upfront, and instructions can be adjusted mid-response.
Safety
GPT‑5.4 includes enhanced safeguards:
- Expanded cyber safety stack with monitoring systems, trusted access controls, and asynchronous blocking for high-risk requests.
- Low Chain-of-Thought (CoT) controllability, supporting effective monitoring and reducing potential for reasoning obfuscation.
- Precautionary deployment on Zero Data Retention (ZDR) surfaces, with ongoing classifier improvements to minimize false positives.
Availability and Pricing
- ChatGPT: GPT‑5.4 Thinking replaces GPT‑5.2 Thinking for Plus, Team, and Pro users; GPT‑5.2 remains in Legacy Models for three months. GPT‑5.4 Pro is available to Pro and Enterprise users.
- API & Codex: Available as
gpt-5.4andgpt-5.4-pro. Experimental 1 M token context support can be configured viamodel_context_windowandmodel_auto_compact_token_limit. Requests beyond 272K context count at double usage.
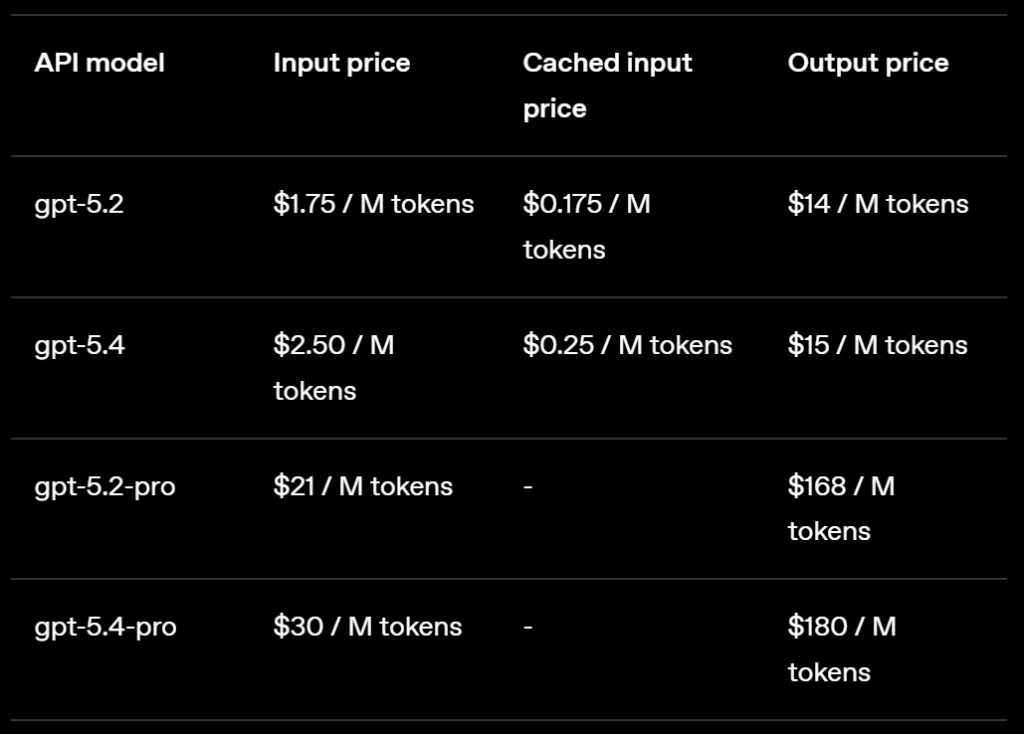
- Pricing: Higher per-token rate than GPT‑5.2; batch and flex pricing at half rate, priority processing at double rate.