
OpenAI has released a research preview of GPT‑5.3‑Codex‑Spark, a smaller and faster version of GPT‑5.3‑Codex, designed for real-time coding tasks. The model is optimized for ultra-low latency hardware in partnership with Cerebras, delivering more than 1,000 tokens per second while maintaining full coding capability.
Codex-Spark is intended for interactive coding, enabling targeted edits, logic updates, or interface adjustments with immediate results. It also complements longer-running tasks handled by other Codex models. At launch, the model supports a 128k context window and is text-only. Usage during the research preview follows separate rate limits and may be temporarily limited under high demand.
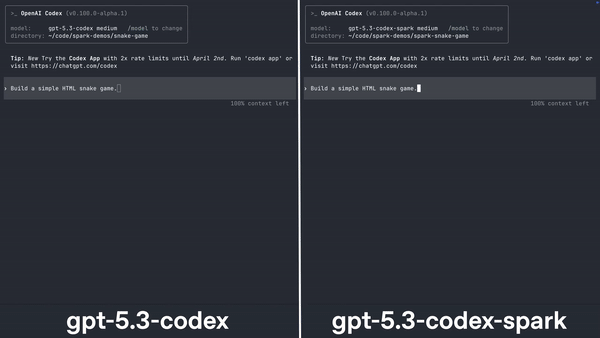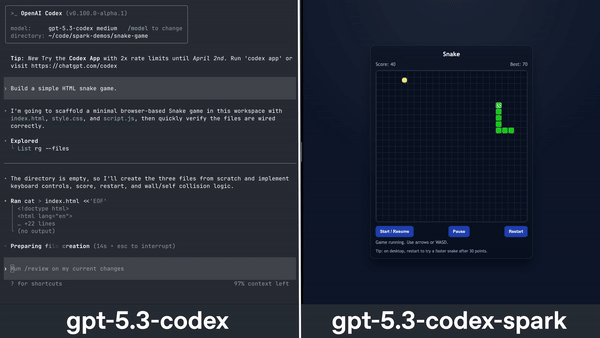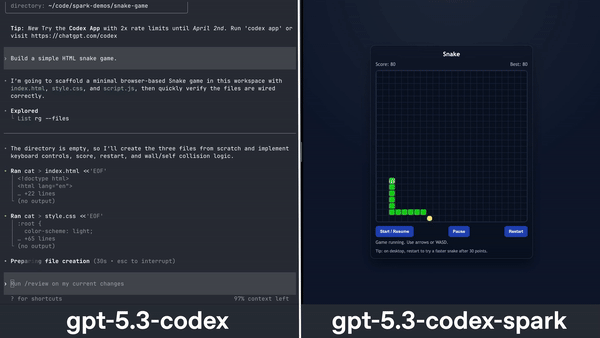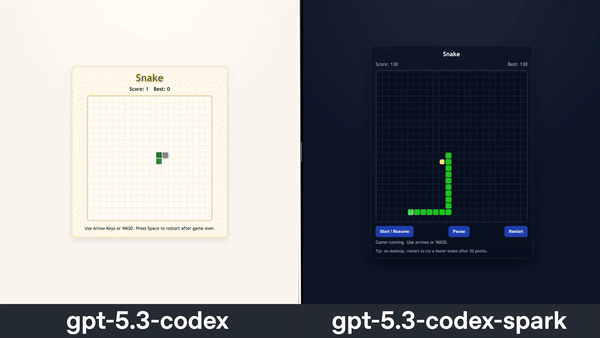
Features: GPT‑5.3‑Codex‑Spark
- Interactive Performance: Optimized for low-latency editing; by default, it performs minimal edits and does not run tests unless requested.
- Coding Benchmarks: Evaluated on SWE-Bench Pro and Terminal-Bench 2.0, achieving high accuracy and completing tasks faster than GPT‑5.3‑Codex.
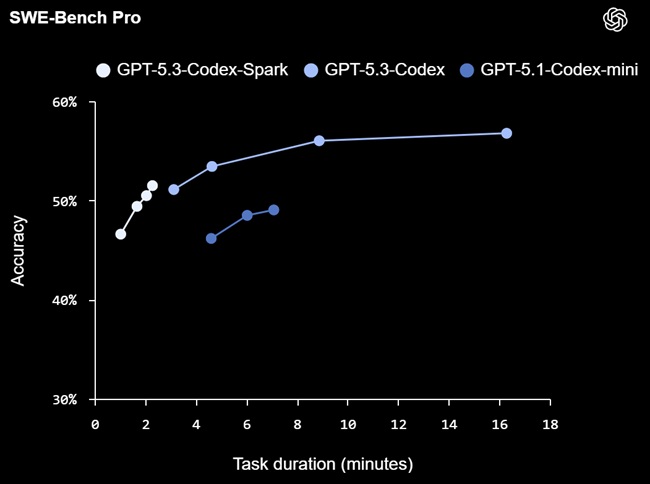
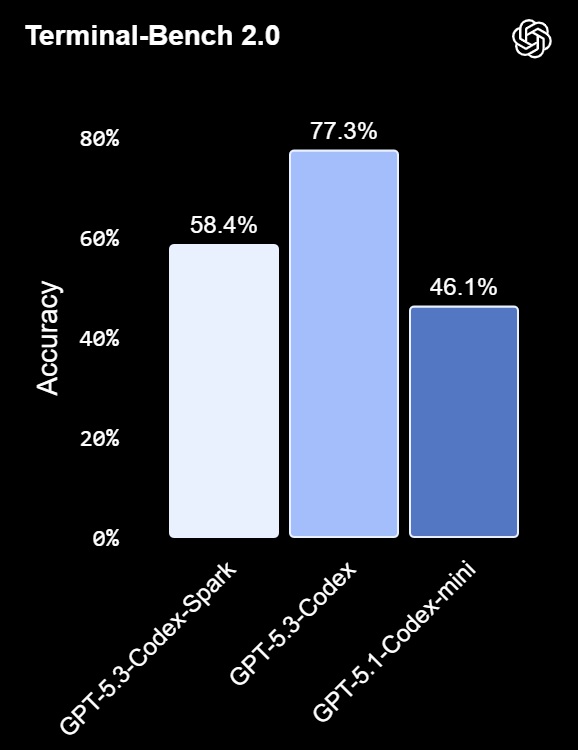
- Latency Improvements: End-to-end optimizations reduce client-server roundtrip overhead by 80%, per-token overhead by 30%, and time-to-first-token by 50%. The model uses a persistent WebSocket connection by default.
- Hardware Integration: Runs on Cerebras Wafer Scale Engine 3, providing low-latency inference. GPUs continue to support large-scale, cost-efficient workloads, while Cerebras accelerators enhance interactive coding responsiveness.
- Dual Coding Modes: Supports both real-time, interactive coding and longer-horizon tasks.
- Safety and Evaluation: Includes standard safety training, including cyber-relevant guidance. Codex-Spark was assessed under OpenAI’s deployment framework and is not expected to reach high-risk thresholds for cybersecurity or biological capabilities.
What’s Next
The company says Codex-Spark is the first step toward a Codex with two complementary modes—longer-horizon reasoning and real-time collaboration—and expects that over time these modes will blend, keeping users in a tight interactive loop while delegating longer-running tasks to sub-agents or multiple models in parallel.
The company notes that as models become more capable, interaction speed becomes a bottleneck, and ultra-fast inference tightens the loop, making Codex feel more natural to use and expanding what the company expects is possible for anyone turning an idea into working software.
Availability
- Research Preview: Available today for ChatGPT Pro users via the Codex app, CLI, and VS Code extension.
- API Access: Limited availability for design partners; broader access will be rolled out in stages.
- Context and Input: Currently supports text-only input with a 128k context window. Future releases may include multimodal input and larger models.