
Google DeepMind has introduced Gemma 4 12B, a new open-weight multimodal model designed to bring agentic intelligence directly to laptops with mobile-first efficiency and advanced reasoning.
Gemma 4 12B sits between the edge-friendly E4B model and the larger 26B Mixture-of-Experts (MoE) model, offering strong performance with a reduced memory footprint. It is also the first mid-sized model in the series to feature native audio input support.
The Gemma family has now crossed 150 million downloads, with developers building use cases ranging from wearable robotic arms for physical assistance to enterprise-grade AI security systems.
Key features of Gemma 4 12B
Gemma 4 12B introduces a unified encoder-free multimodal architecture, where vision and audio inputs flow directly into the LLM backbone without separate encoders. This reduces latency and memory overhead compared to traditional multimodal systems.
- Vision processing: Replaces the vision encoder with a lightweight embedding module using a single matrix multiplication, positional embeddings, and normalizations
- Audio processing: Removes the audio encoder entirely and projects raw audio signals into the same token space as text
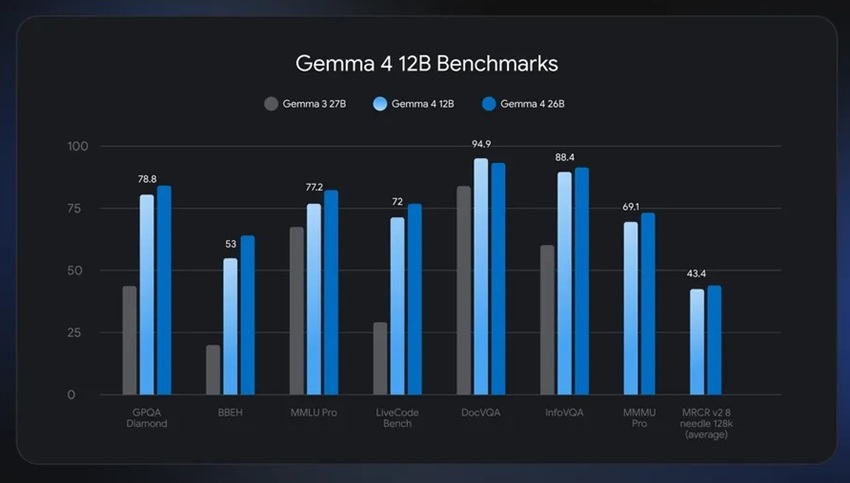
The model delivers benchmark performance close to the 26B MoE model while using less than half the memory footprint, enabling multi-step reasoning and agentic workflows on laptops with 16GB VRAM or unified memory.
Gemma 4 12B is released under the Apache 2.0 license and includes Multi-Token Prediction (MTP) drafters to improve inference speed and reduce latency.
It supports advanced agentic capabilities such as:
- Autonomous data processing
- Generating rich visual insights
- Building fully functional webpages
- Executing everyday tool use and workflows
- Multi-step reasoning and structured task execution
A new Gemma Skills Repository is also introduced, providing an official library of reusable skills designed specifically for building agentic systems with Gemma models.
Run state-of-the-art agents locally
Gemma 4 12B delivers near-26B MoE performance on benchmarks while requiring significantly lower memory, making it suitable for:
- Local AI agents
- On-device reasoning systems
- Private offline workflows
- Edge and laptop-based AI applications
Experience a uniquely efficient unified architecture
Traditional multimodal systems rely on separate encoders for vision and audio, which increases latency and memory usage. Gemma 4 12B removes this limitation through a fully unified design.
- No separate encoders for vision or audio
- Direct processing inside LLM backbone
- Reduced latency and memory consumption
- Improved cross-modal reasoning consistency
Vision pipeline
Vision is handled through a lightweight embedding module with a single matrix multiplication, positional embeddings, and normalizations, replacing the full vision encoder.
Audio pipeline
Audio is processed by removing the encoder entirely and projecting raw audio signals directly into the same embedding space as text tokens.
Performance Benchmarks
Gemma 4 12B shows performance differences across Linux and macOS GPU environments, measuring prefill speed, decode speed, latency, and memory usage.
Linux
- Device: AMD Radeon™ AI PRO R9700
- Backend: GPU
- Prefill: 662.32 tokens/sec
- Decode: 66.26 tokens/sec
- Time-to-first-token: 1.56 sec
- Model size: 6235 MB
- GPU Memory: 8064.2 MB
macOS
- Device: MacBook Pro M4
- Backend: GPU
- Prefill: 243.55 tokens/sec
- Decode: 29.56 tokens/sec
- Time-to-first-token: 4.2 sec
- Model size: 6235 MB
- GPU Memory: 7763 MB
Get started today
Developers can try Gemma 4 12B using:
- LM Studio
- Ollama
- Google AI Edge Gallery
- Google AI Edge Eloquent
- LiteRT-LM
They can also:
- Download weights from Hugging Face and Kaggle
- Review developer documentation and quick start notebook
- Use frameworks like Hugging Face Transformers, llama.cpp, MLX, SGLang, and vLLM
- Fine-tune using Unsloth
- Spin up production endpoints using Google Cloud
Gemma Skills Repository
The model includes an official Skills Repository, designed to help developers build agentic systems using reusable Gemma capabilities.
Bringing Gemma 4 12B to your laptop
Gemma 4 12B is designed for local execution on everyday machines using the Google AI Edge stack.
This enables:
- Autonomous data processing
- Generating rich visual insights
- Building fully functional webpages
- Everyday tool execution
- Fully local agent workflows
Coding and advanced workflows
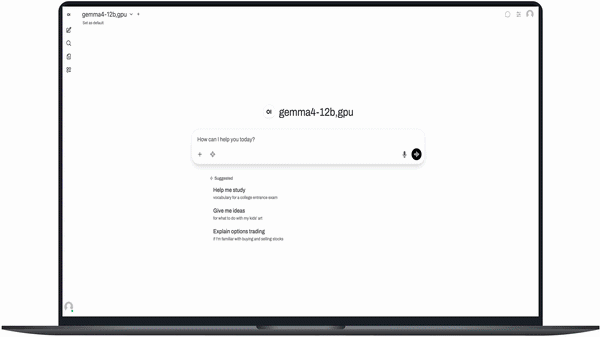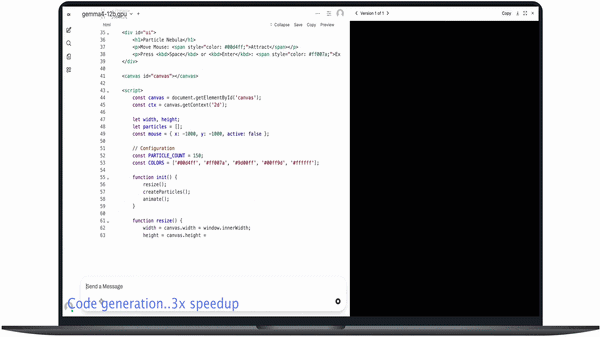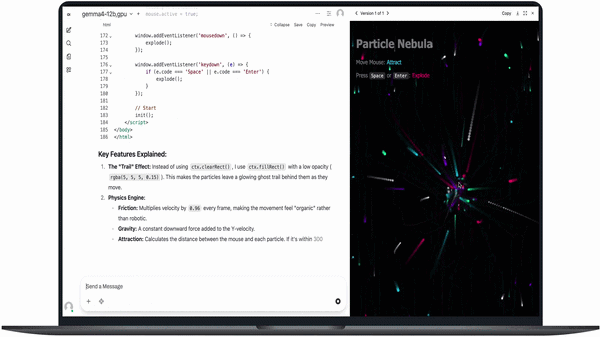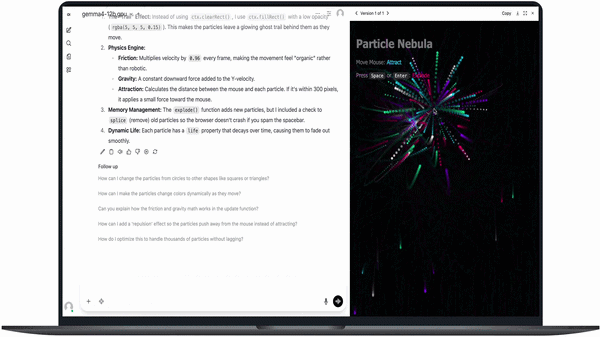
Gemma 4 12B supports advanced local execution capabilities including:
- Python code generation from natural language prompts
- Local execution of scripts and data analysis
- Automatic chart generation from datasets
- Self-correcting code generation in a single turn
- Complex 3D rendering tasks with dependency handling
- End-to-end webpage generation
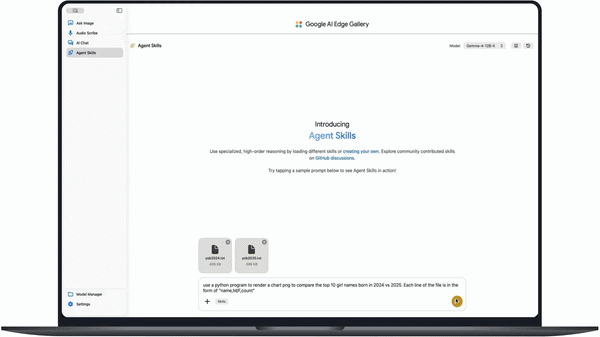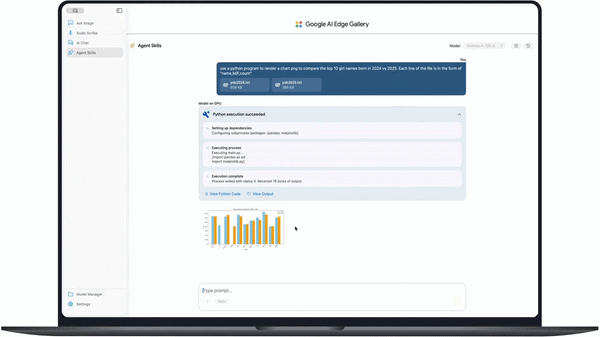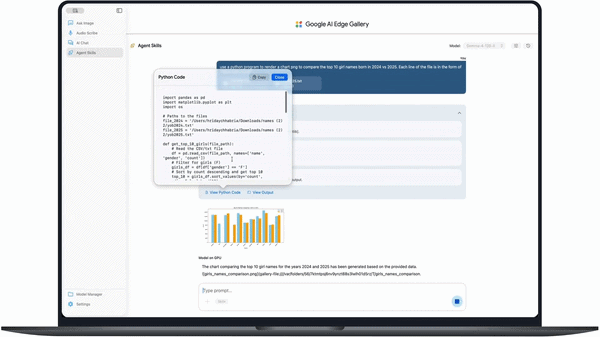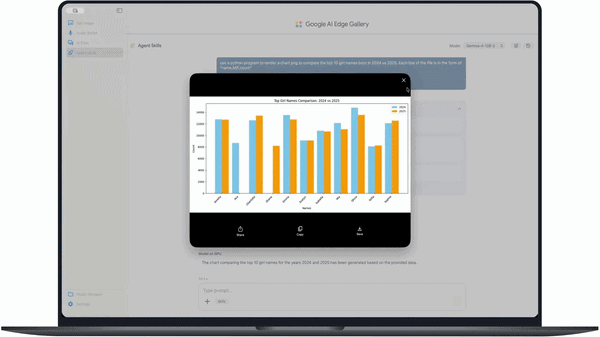
In coding tests, the model can generate outputs such as charts from datasets (e.g., comparing baby names across years) and even render 3D scenes with full dependency setup and correction in a single prompt.
Dictation and voice-driven editing
Google AI Edge Eloquent is a fully on-device macOS application that transforms speech into structured writing.
It provides:
- System-wide voice dictation via hotkeys
- Fully local transcription of audio and video files
- Voice-based text editing (Voice Edit feature)
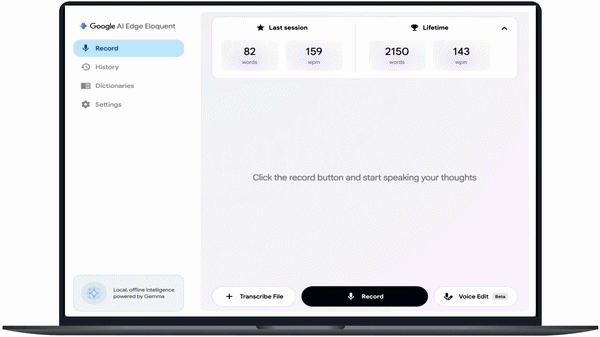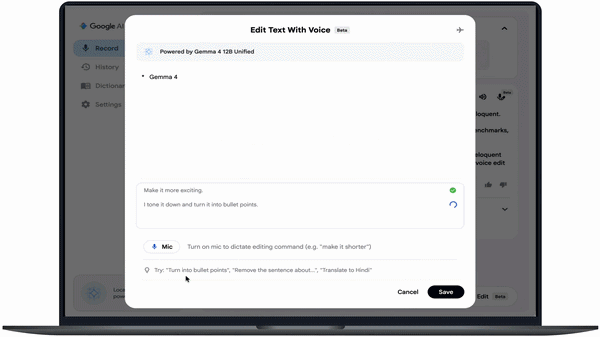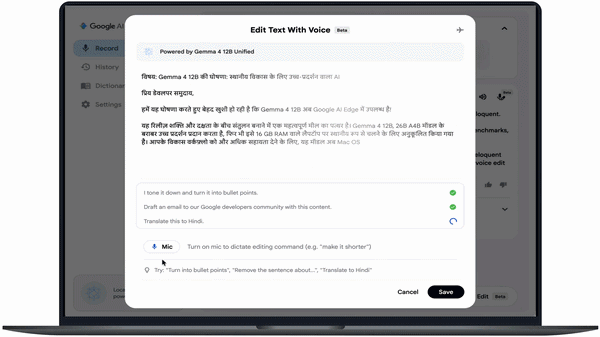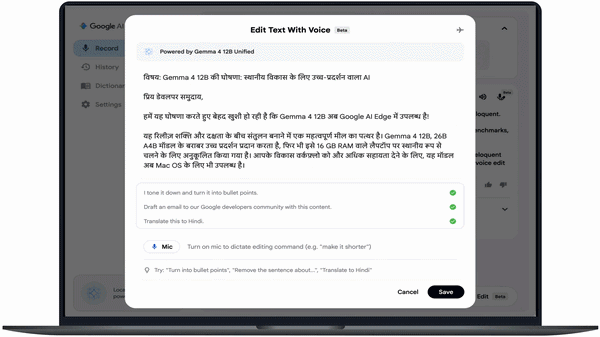
Users can issue commands such as:
- “Restructure these notes into an executive summary”
- “Translate this into Hindi”
Gemma 4 12B improves instruction following, scope adherence, and output quality compared to previous models, with a reported 60%+ improvement.
LiteRT-LM and local serving
LiteRT-LM introduces a new serve command, turning it into a drop-in local LLM server.
This allows:
- Standard API endpoints for local models
- Drop-in replacement for hosted LLM servers
- Integration with tools like Continue, Aider, OpenCode, Hermes, and Pi
- Fully local agent workflows
- Zero-code model deployment
Deployment options
Gemma 4 12B can be deployed across:
- LM Studio, Ollama, Hugging Face Transformers, llama.cpp, MLX, SGLang, vLLM
- Google Cloud endpoints
- Gemini Enterprise Agent Platform Model Garden
- Cloud Run and Google Kubernetes Engine (GKE)
Availability
Gemma 4 12B is available as an open-weight model under the Apache 2.0 license and can be downloaded from Hugging Face and Kaggle.
It is optimized for laptops with 16GB memory and supports fully offline multimodal AI workflows.
It is integrated across the Google AI Edge ecosystem, including macOS tools such as AI Edge Gallery, Eloquent, and LiteRT-LM CLI, enabling local-first AI experiences while keeping all data on-device.