
OpenAI has introduced two open-weight models, gpt-oss-120b and gpt-oss-20b, under the Apache 2.0 license. These models deliver advanced reasoning capabilities, efficient deployment options, and support a broad range of use cases, including on-device inference.
Why These Open Models Matter
OpenAI aims to broaden access to powerful AI systems by releasing models that developers can run, inspect, and customize. These models provide alternatives to proprietary systems, enabling safer deployment, research, and innovation, especially in sectors and regions with limited resources. They also support local inference, global access, and transparent AI development.
Model Specifications: gpt-oss-120b and gpt-oss-20b
Both models use Transformer architecture enhanced with Mixture-of-Experts (MoE). They support context lengths up to 128k tokens using Rotary Positional Embeddings (RoPE), alongside grouped multi-query attention and locally banded sparse attention for efficient processing.
gpt-oss-120b
- Layers: 36
- Total Parameters: 117 billion
- Active Parameters Per Token: 5.1 billion
- Total Experts: 128
- Active Experts Per Token: 4
- Context Length: 128k tokens
- Minimum RAM Required: 80 GB GPU
- Benchmark Standing: Matches or exceeds OpenAI o4-mini
gpt-oss-20b
- Layers: 24
- Total Parameters: 21 billion
- Active Parameters Per Token: 3.6 billion
- Total Experts: 32
- Active Experts Per Token: 4
- Context Length: 128k tokens
- Minimum RAM Required: 16 GB
- Benchmark Standing: Similar to OpenAI o3-mini; runs efficiently on-device
Reasoning and Tool Use
Both models excel on benchmarks such as:
- TauBench (tool use and agentic reasoning)
- HealthBench (health-related queries)
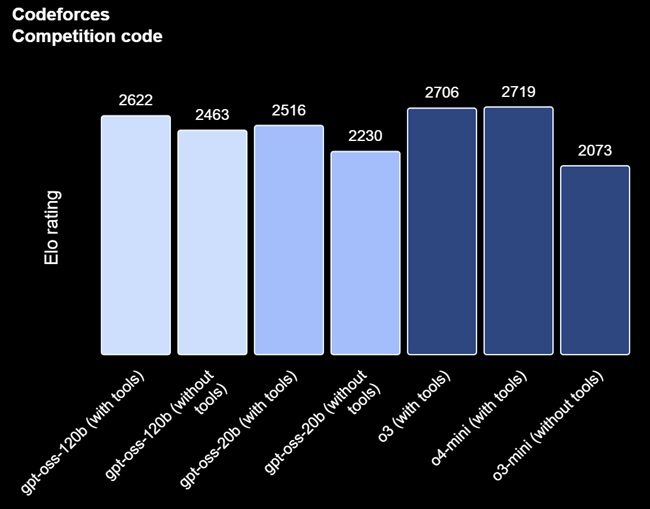
- AIME (competition mathematics)
- MMLU, HLE, and Codeforces (general knowledge and coding evaluations)
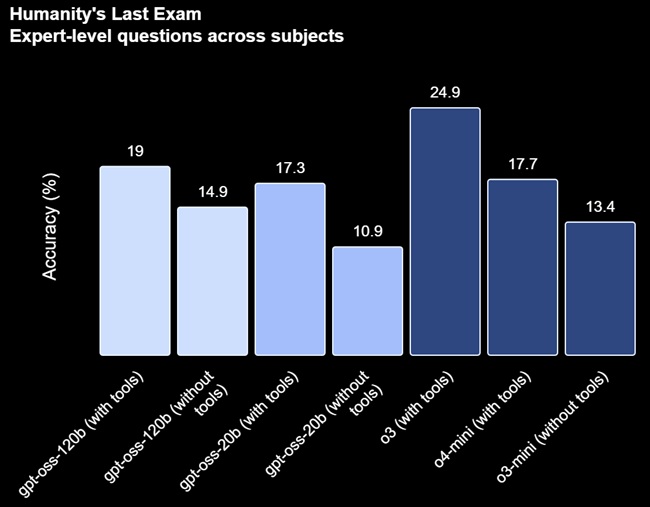
The gpt-oss-120b matches OpenAI’s o4-mini and outperforms o3-mini on many reasoning benchmarks, while the smaller gpt-oss-20b meets or exceeds o3-mini in various tests.
Post-Training and Alignment
The models underwent supervised fine-tuning followed by high-compute reinforcement learning (RL) stages. They support:
- Structured outputs
- Full chain-of-thought (CoT) reasoning
- Users can adjust reasoning modes—low, medium, or high—via system instructions.
Safety and Evaluation
OpenAI applied several safety measures:
- Pre-training filters excluded high-risk data (e.g., Chemical, Biological, Radiological, Nuclear content)
- Post-training involved deliberative alignment and refusal training
- Adversarial fine-tuning tested risks under misuse scenarios, confirming low risk
- The models meet OpenAI’s internal safety benchmarks and Preparedness Framework
Note: Chain-of-thought outputs are not supervised and may contain hallucinations or harmful content. Developers should avoid exposing CoTs directly to end users.
To boost safety studies, OpenAI launched a $500K Red Teaming Challenge, releasing findings and evaluation data openly.
Availability and Deployment
- Weights: Freely downloadable on Hugging Face
- Quantization: MXFP4 format enables efficient memory use—80GB for 120B and 16GB for 20B models.
- Tokenizer: Open-sourced o200k_harmony tokenizer
- Inference tools: Ready-to-use examples for PyTorch and Apple Metal platforms.
- Prompt renderer: Available in Python and Rust
Deployment support includes:
- Cloud/hosting providers: Azure, AWS, Vercel, Hugging Face, Databricks, OpenRouter, Together AI, LM Studio, Fireworks, Baseten
- Local and edge platforms: llama.cpp, Ollama, Qualcomm AI Hub, Foundry Local (Windows)
- Hardware vendors: NVIDIA, AMD, Apple Metal, ONNX Runtime, Groq, Cerebras
GPU-optimized versions are also available for Windows devices via VS Code and Foundry Local using ONNX Runtime.
Snapdragon Integration and On-Device Inference
Qualcomm Technologies is supporting OpenAI’s GPT-OSS models on Snapdragon platforms, with deployment expected to begin in 2025. The gpt-oss-20b model runs entirely on Snapdragon-powered devices, enabling local AI inference without relying on cloud services.
Early integration testing with Qualcomm’s AI Engine and AI Stack has demonstrated the model’s capability to perform complex reasoning fully on-device. Developers will access the model through platforms like Hugging Face and Ollama, which integrates a lightweight open-source LLM servicing framework tailored for Snapdragon devices.
Key highlights:
- On-device chain-of-thought reasoning optimized for Snapdragon processors
- Access via Hugging Face and Ollama platforms
- Ollama supports web search and turbo mode
- Deployment on smartphones, PCs, XR headsets, and vehicles
Qualcomm expects ongoing improvements in mobile memory and software efficiency to drive growth in on-device AI, enabling more private, low-latency, and personalized AI experiences.