
Xiaomi has introduced MiMo, its first open-source artificial intelligence large language model, designed for reasoning tasks. Developed by the newly formed Xiaomi Big Model Core Team, the 7-billion-parameter model excels in mathematical reasoning and code generation, matching the performance of larger models like OpenAI’s o1-mini and Alibaba’s Qwen-32B-Preview.
Xiaomi noted that achieving such capabilities in a smaller model is challenging, as most successful reinforcement learning (RL) models rely on larger architectures, such as 32-billion-parameter models.
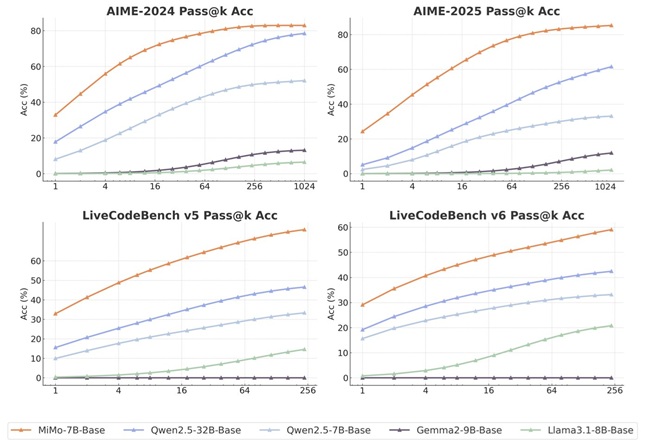
The company believes MiMo’s effectiveness in reasoning is driven by the base model’s potential, enabled through focused pre-training and post-training strategies. Its smaller size may make it suitable for enterprise use and edge devices with limited resources.
Pre-Training Process
MiMo’s reasoning ability is built on an optimized pre-training process. Xiaomi improved its data preprocessing pipeline, enhanced text extraction tools, and used multi-layered filtering to increase the density of reasoning patterns.
The team compiled a dataset of 200 billion reasoning tokens and applied a three-stage data mixture strategy. The model was trained on 25 trillion tokens over three progressive training phases. Xiaomi also used Multiple-Token Prediction as a training objective to boost performance and reduce inference time.
Post-Training Process
In the post-training stage, Xiaomi applied reinforcement learning using 130,000 mathematics and coding problems, verified by rule-based systems for accuracy and difficulty. To address sparse rewards in complex tasks, the team implemented a Test Difficulty Driven Reward system and used Easy Data Re-Sampling for stable RL training on easier problems.
To improve training and validation speed, Xiaomi introduced a Seamless Rollout Engine that cuts down GPU downtime. This system delivered a 2.29× increase in training speed and a 1.96× boost in validation. It also supports Multiple-Token Prediction in vLLM and enhances the RL system’s inference stability.
MiMo AI Model Variants
The MiMo-7B series includes four versions:
- MiMo-7B-Base: Base model with strong reasoning potential
- MiMo-7B-RL-Zero: RL model trained from the base
- MiMo-7B-SFT: Supervised fine-tuned model
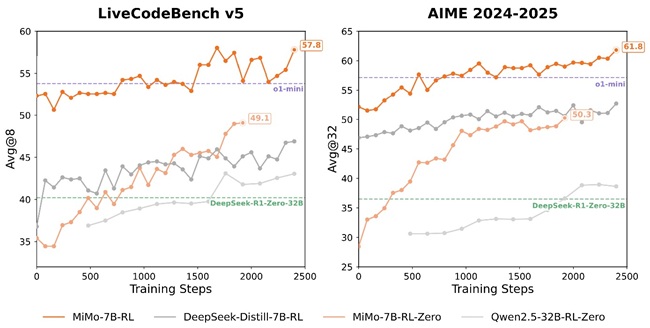
- MiMo-7B-RL: RL model trained from SFT, offering top-tier performance matching OpenAI’s o1-mini
Benchmark Performance
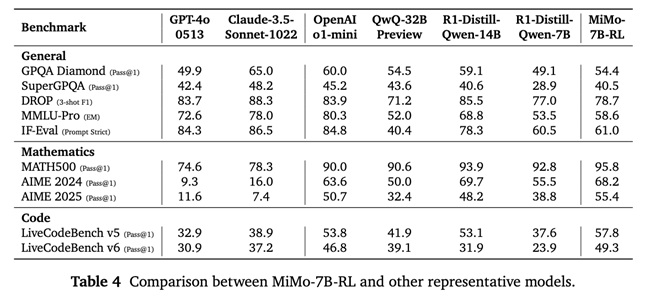
MiMo-7B-RL delivered strong performance across various evaluations (temperature = 0.6):
Mathematics:
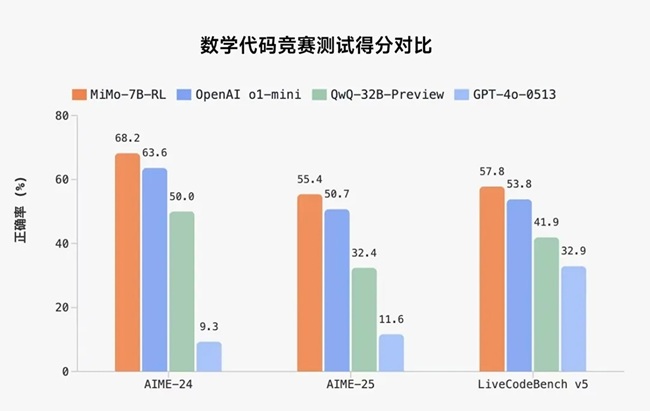
- MATH-500: 95.8% Pass@1 (single run)
- AIME 2024: 68.2% Pass@1 (avg. of 32 runs)
- AIME 2025: 55.4% Pass@1 (avg. of 32 runs)
Code:
- LiveCodeBench v5: 57.8% Pass@1 (avg. of 8 runs)
- LiveCodeBench v6: 49.3% Pass@1 (avg. of 8 runs)
General:
- GPQA Diamond: 54.4% Pass@1 (avg. of 8 runs)
- SuperGPQA: 40.5% Pass@1 (single run)
- DROP (3-shot F1): 78.7
- MMLU-Pro (Exact Match): 58.6
- IF-Eval (Prompt Strict): 61.0 (avg. of 8 runs)
Availability
The MiMo-7B model series is open-source and accessible on Hugging Face. The full technical report and model checkpoints are also available on GitHub.