
Xiaomi has officially open-sourced the MiMo-V2.5 model series under the MIT License. The release enables commercial use, continued training, and fine-tuning without additional authorization.
The series includes two models designed for different workloads:
- MiMo-V2.5-Pro: Focused on complex agentic tasks, coding, and long-horizon reasoning
- MiMo-V2.5: A native omnimodal model built for multimodal understanding and agent capabilities
Both models support a 1M-token context window and are based on a Sparse Mixture-of-Experts (MoE) architecture with a hybrid attention design.
MiMo-V2.5
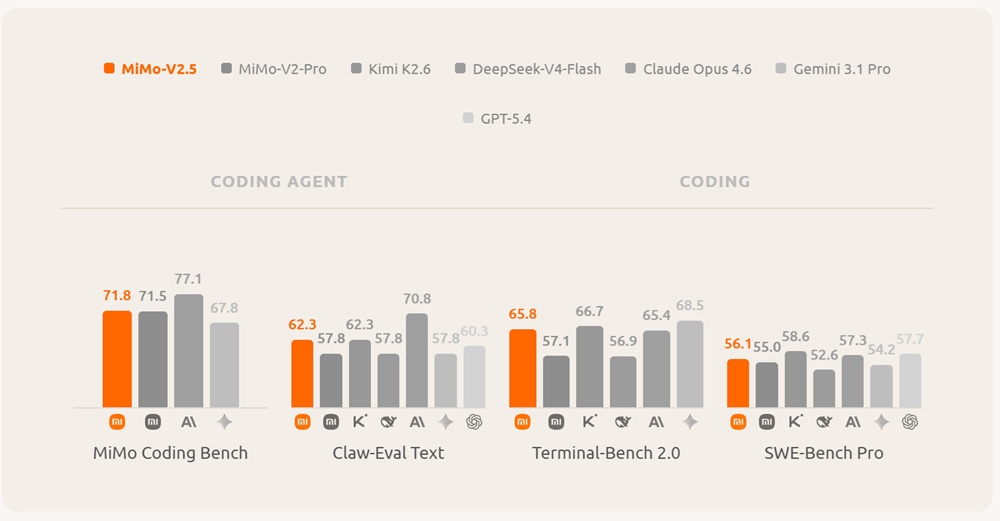
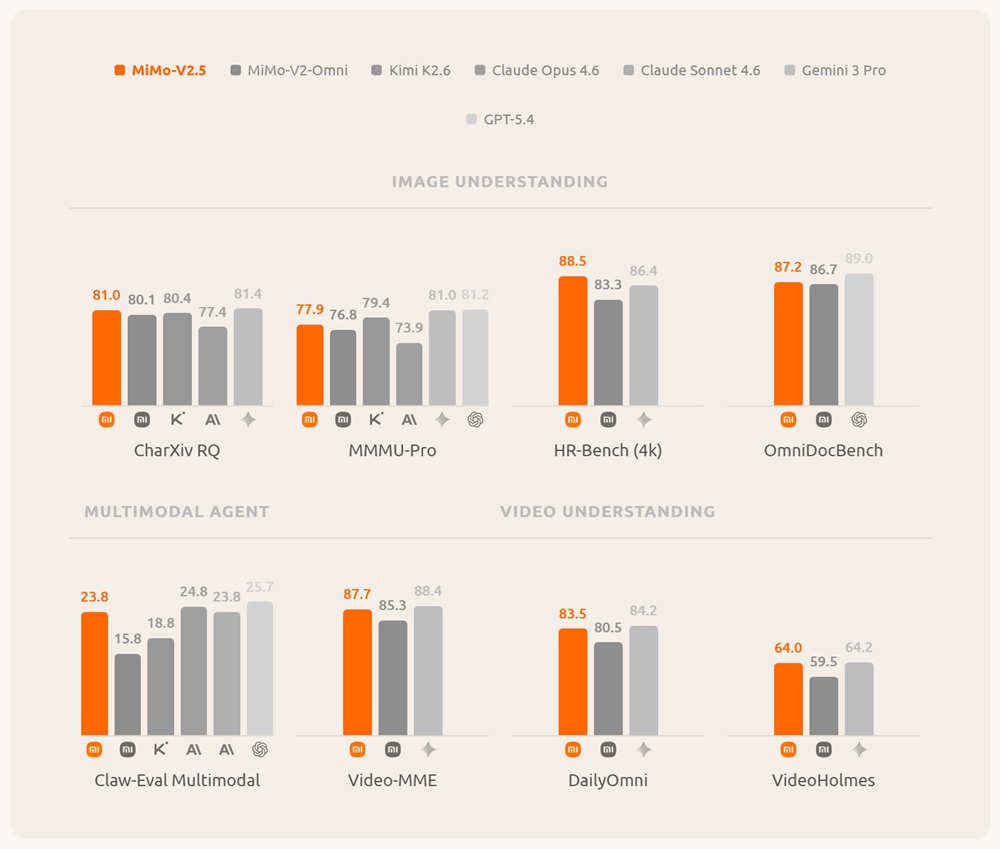
MiMo-V2.5 is a native omnimodal model designed to process text, image, video, and audio within a unified system. It targets multimodal reasoning, perception, and agent-style workflows.
The model has 310B total parameters with 15B active parameters and is trained on approximately 48 trillion tokens. It is built on the MiMo-V2-Flash hybrid sliding-window attention backbone and integrates dedicated vision and audio encoders through lightweight projection layers.
Core Capabilities
MiMo-V2.5 supports unified multimodal understanding across multiple input types:
- Text, image, video, and audio processing in a single model
- Long-context reasoning up to 1M tokens
- Multimodal agent execution and tool interaction
- Unified perception-to-action workflow
Architecture Overview
The model integrates multiple components into a single architecture:
- Hybrid attention combining Sliding Window Attention and Global Attention
- 729M-parameter Vision Transformer with hybrid window design
- Audio encoder derived from MiMo-Audio tokenizer weights
- Multi-Token Prediction (MTP) modules for improved inference efficiency
Training Pipeline
MiMo-V2.5 is trained through five structured stages:
- Large-scale text pre-training for foundational language capability
- Projector warmup to align vision and audio encoders
- Multimodal pre-training on cross-modal datasets
- Supervised fine-tuning with agentic training and progressive context scaling (32K → 256K → 1M)
- Reinforcement learning and Multi-Teacher On-Policy Distillation (MOPD)
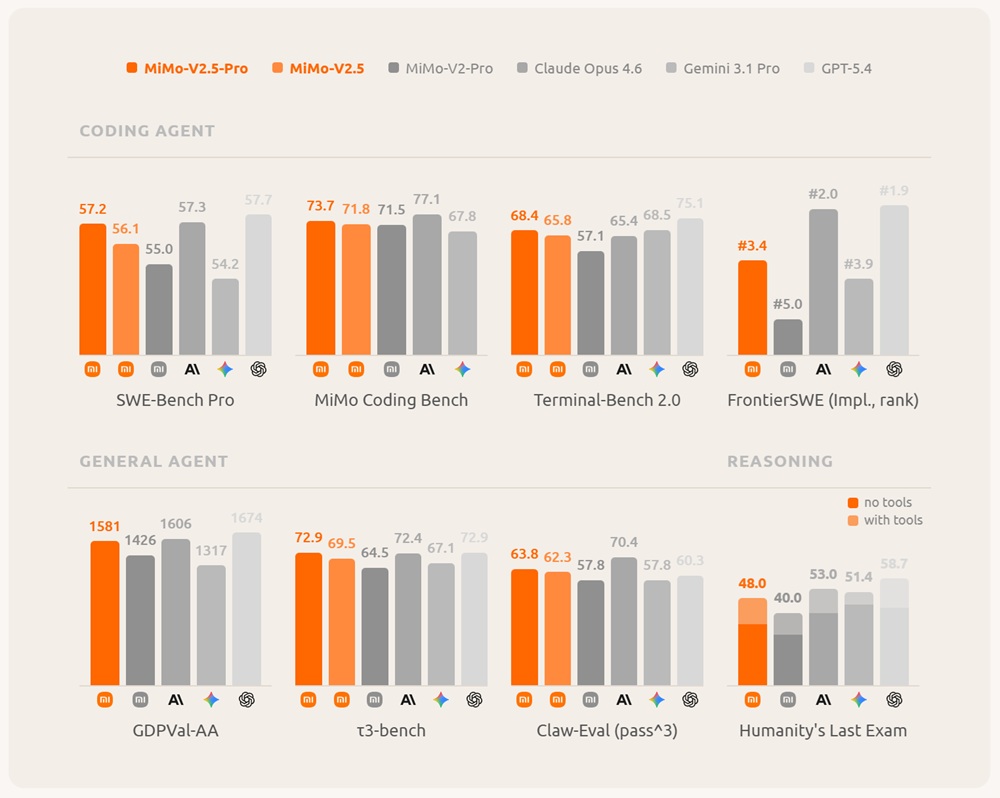
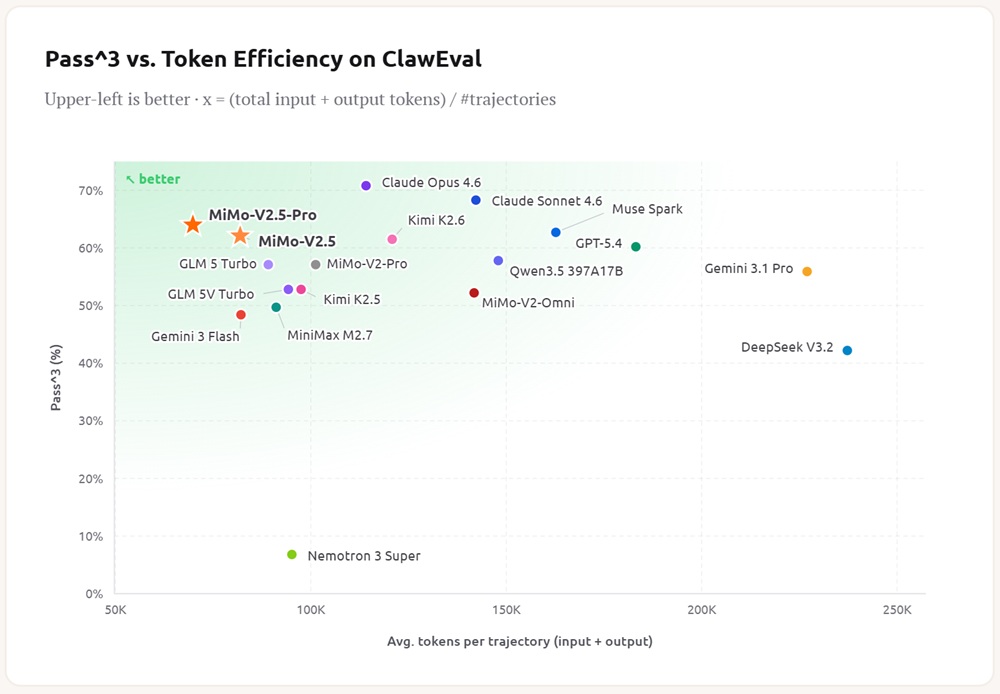
MiMo-V2.5-Pro
MiMo-V2.5-Pro is the most capable model in the series, designed for advanced coding, software engineering, and long-horizon autonomous agent tasks.
It is a 1.02T-parameter Mixture-of-Experts model with 42B active parameters, supporting a 1M-token context window. It is built using a hybrid attention architecture optimized for long-context efficiency and stability.
Architecture Design
- Hybrid attention with 6:1 Sliding Window to Global Attention ratio
- Approximately 7× KV-cache reduction
- Native Multi-Token Prediction (3-layer MTP)
- Support for 1M-token context processing
Training Strategy
The model is trained through a multi-stage pipeline:
- Pre-training on 27T tokens using FP8 mixed precision
- Supervised Fine-Tuning (SFT) for instruction learning
- Domain-specific reinforcement learning (coding, math, safety, agent tasks)
- Multi-Teacher On-Policy Distillation (MOPD)
- Progressive context extension up to 1M tokens
Agentic and Coding Performance
MiMo-V2.5-Pro is optimized for long-running autonomous workflows and structured reasoning tasks. It is capable of:
- Sustaining 1000+ tool-call sequences in a single task
- Maintaining coherence across extended reasoning chains
- Handling complex software engineering workflows
- Executing multi-step agent operations
It has been evaluated on large-scale tasks including compiler construction, full application generation, and circuit design optimization.
Model Specifications
Both MiMo-V2.5 and MiMo-V2.5-Pro are built on Sparse Mixture-of-Experts architecture with hybrid attention and long-context support.
| Model | Total Params | Active Params | Context Length | Precision |
|---|---|---|---|---|
| MiMo-V2.5-Base | 310B | 15B | 256K | FP8 (E4M3) Mixed |
| MiMo-V2.5 | 310B | 15B | 1M | FP8 (E4M3) Mixed |
| MiMo-V2.5-Pro-Base | 1.02T | 42B | 256K | FP8 (E4M3) Mixed |
| MiMo-V2.5-Pro | 1.02T | 42B | 1M | FP8 (E4M3) Mixed |
Token Plan Update
The token system has been simplified across the model series:
- MiMo-V2.5 — 1x (1 token = 1 credit)
- MiMo-V2.5-Pro — 2x (1 token = 2 credits)
Availability
The MiMo-V2.5 series is fully open-sourced under the MIT License, allowing commercial use, continued training, and fine-tuning without additional authorization.
Both models are available for download and access via Hugging Face, along with model weights, tokenizer, and full model cards.
Deployment Support
The models are compatible with modern inference frameworks:
- SGLang (recommended for long-context optimization)
- vLLM (community-supported deployment)
Both support efficient inference for workloads up to 1M tokens.