
Google DeepMind has introduced Agentic Vision in Gemini 3 Flash, a new capability that changes how the model understands images. Instead of analyzing visuals in a single, static pass, the model can now actively investigate images through step-by-step reasoning supported by code execution.
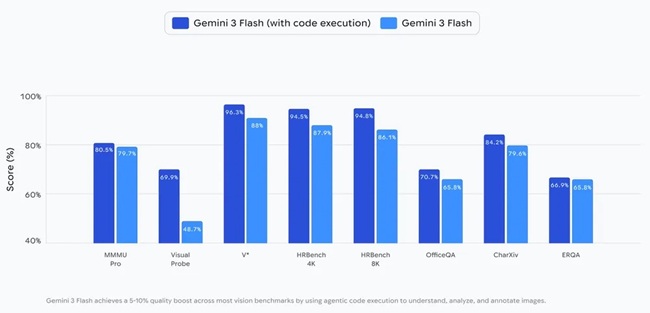
Google states that enabling code execution with Gemini 3 Flash results in a 5–10% quality improvement across most vision benchmarks.
What Is Agentic Vision
Conventional vision models process images in one glance. When fine details—such as small text, distant objects, or tiny components—are overlooked, the model must infer missing information.
Agentic Vision addresses this limitation by combining visual reasoning with executable code. The model treats image understanding as an investigative process, allowing it to zoom into specific areas, manipulate visuals, and verify details before producing a response.
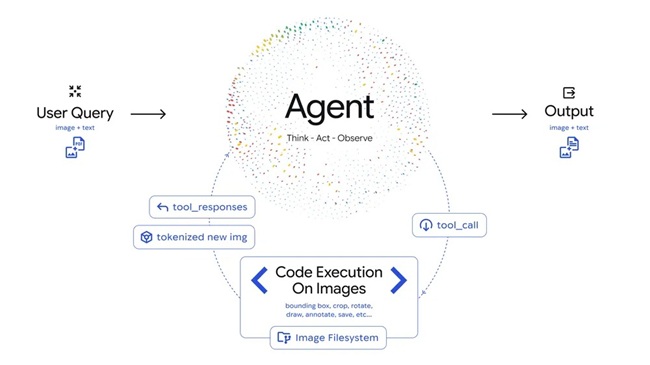
How Agentic Vision Works
Agentic Vision operates through an iterative Think–Act–Observe loop:
- Think: The model analyzes the user query along with the initial image and creates a multi-step plan to extract relevant visual information.
- Act: Gemini 3 Flash generates and executes Python code to manipulate or analyze the image. Supported actions include cropping, rotating, annotating visuals, counting objects, and running calculations.
- Observe: The modified image is added back into the model’s context window, allowing it to re-examine the updated visual data before continuing the reasoning process or producing a final answer.
Agentic Vision in Practical Use
Zooming and Fine-Detail Inspection: Gemini 3 Flash is trained to implicitly zoom when fine-grained visual details are required.
PlanCheckSolver.com, an AI-based building plan validation platform, reported a 5% accuracy improvement after enabling code execution with Gemini 3 Flash. The system uses the model to iteratively crop and analyze high-resolution sections of building plans—such as roof edges and structural components—by appending each cropped image back into the model’s context to verify compliance with building codes.
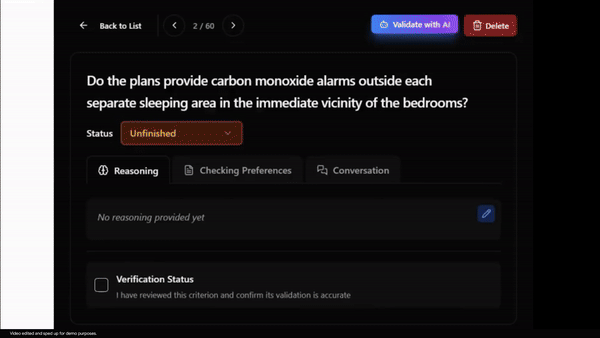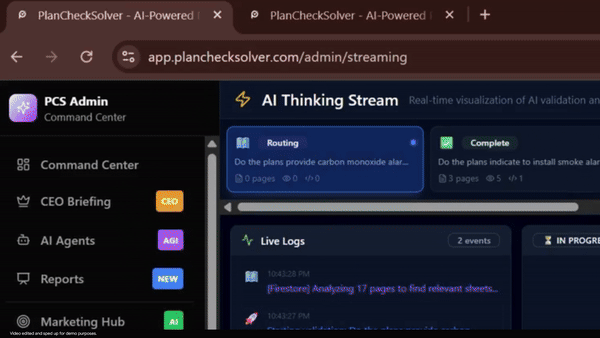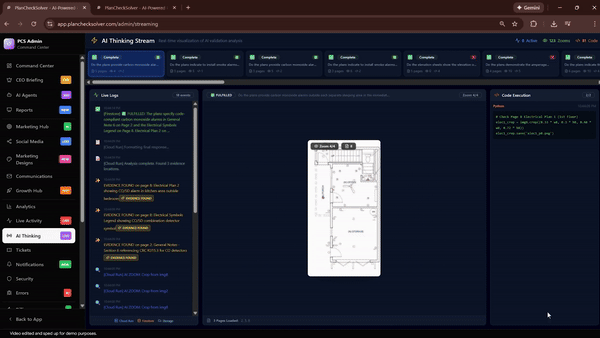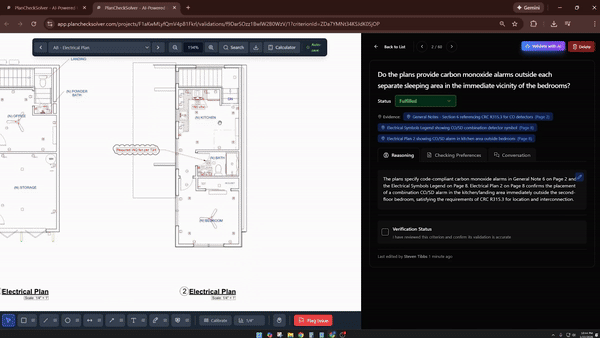
Image Annotation: Agentic Vision enables direct interaction with images through annotation.
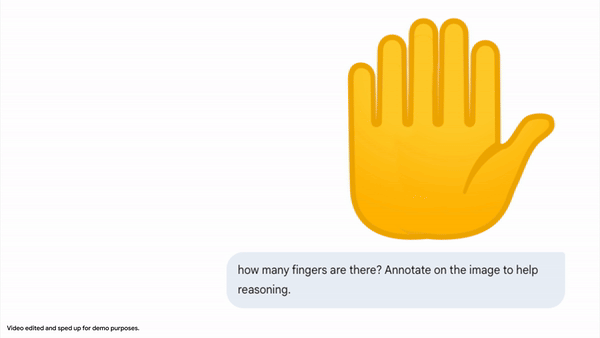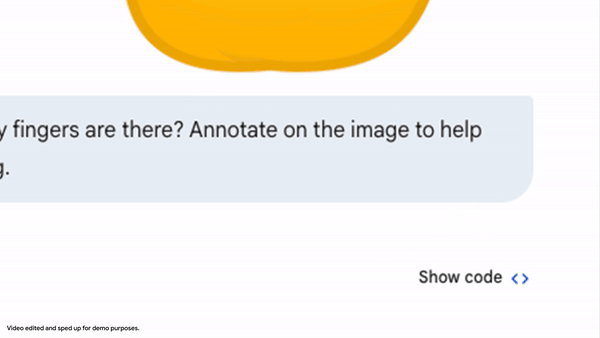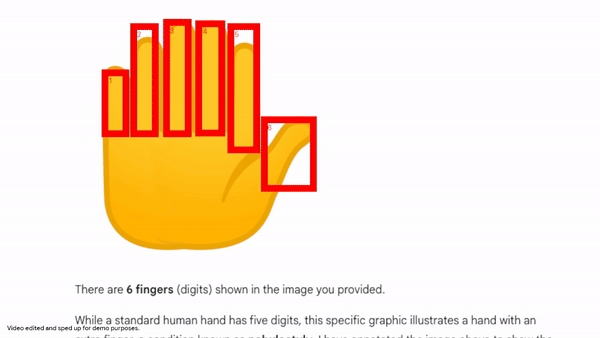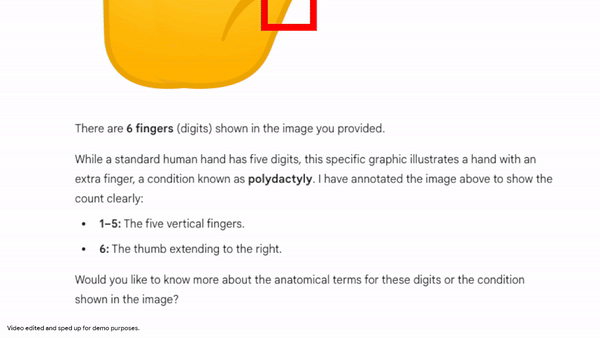
In one example within the Gemini app, the model is asked to count the fingers on a hand. To reduce counting errors, Gemini 3 Flash generates Python code to draw bounding boxes and numeric labels over each detected finger. This annotated image serves as a visual reference, ensuring the final count is grounded in pixel-level inspection.
Visual Math and Data Plotting: Agentic Vision allows the model to extract dense visual data and execute deterministic computations.
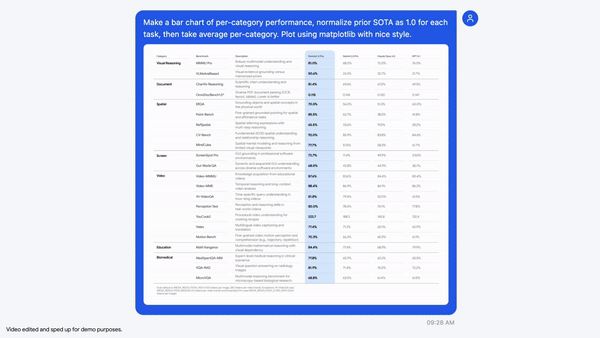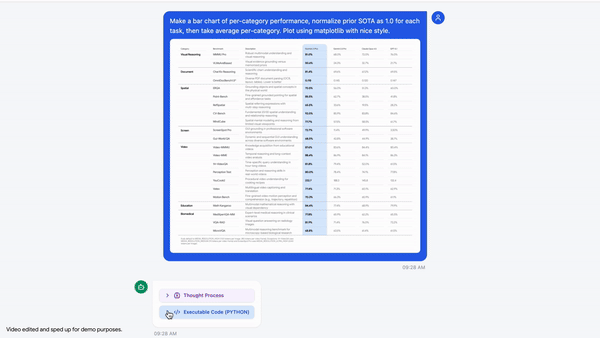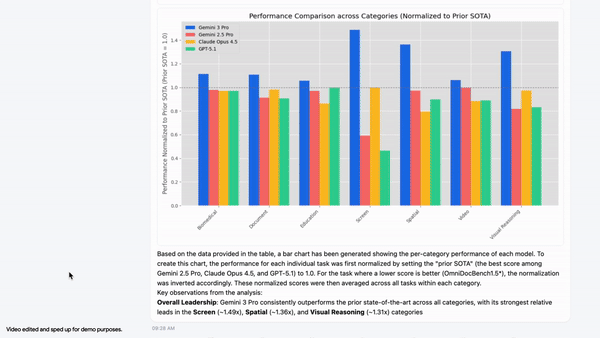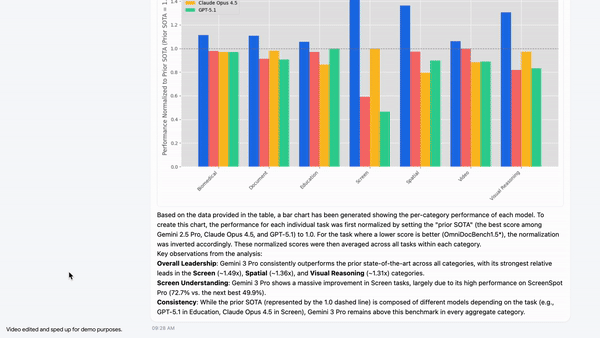
In a demonstration from Google AI Studio, Gemini 3 Flash identifies data from a visual table, generates Python code to normalize values relative to prior state-of-the-art results, and produces a bar chart using Matplotlib. This approach avoids probabilistic estimation and replaces it with verifiable code execution.
What’s Next for Agentic Vision
Google outlined several planned expansions for the capability:
- More implicit code-driven behaviors: While Gemini 3 Flash already performs implicit zooming, other actions—such as rotation and visual math—currently require explicit prompts. These behaviors are expected to become automatic in future updates.
- Additional tools: Google is exploring the integration of tools such as web search and reverse image search to further ground visual understanding.
- Broader model support: Agentic Vision is planned to expand beyond Gemini 3 Flash to other Gemini model sizes.
Availability
Agentic Vision is available through the Gemini API in Google AI Studio and Vertex AI.
- The feature is also beginning to roll out in the Gemini app, accessible by selecting the Thinking model option.
- Developers can test the capability in Google AI Studio by enabling Code Execution under the Tools section in the Playground.