
Google has introduced DiffusionGemma, an experimental open-weight AI model that explores diffusion-based text generation. Released under the Apache 2.0 license, the 26-billion-parameter Mixture-of-Experts (MoE) model moves beyond the sequential token-by-token generation used by traditional autoregressive large language models, instead generating and refining entire blocks of text simultaneously.
Built on the intelligence-per-parameter efficiency of the Gemma 4 family and Google DeepMind’s Gemini Diffusion research, DiffusionGemma incorporates a dedicated diffusion head designed to maximize generation speed.
Google says the model can deliver up to 4x faster text generation on GPUs, making it suitable for researchers and developers exploring speed-critical local AI workflows such as inline editing, rapid iteration and the generation of non-linear text structures.
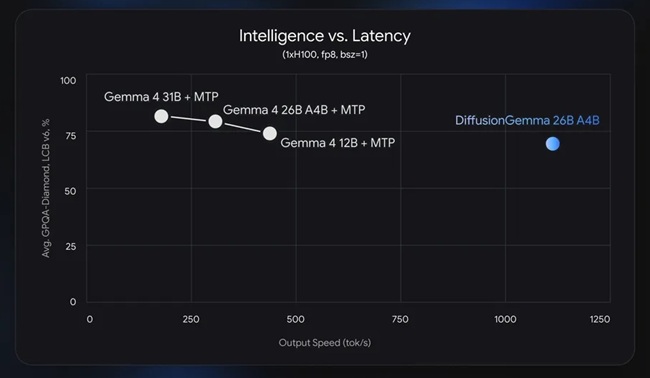
DiffusionGemma focuses on parallel text generation
Unlike traditional autoregressive LLMs that generate text one token at a time, DiffusionGemma uses a diffusion-based approach that generates and refines up to 256 tokens simultaneously.
The model starts with random placeholder tokens and progressively improves them through multiple denoising passes until the text converges into a final output, similar to how diffusion-based image generators transform visual noise into finished images.

Because all tokens can attend to one another through bi-directional attention, DiffusionGemma is particularly suited for tasks such as inline editing, code infilling, mathematical graphs, amino acid sequences and other non-linear text generation workloads.
The iterative refinement process also allows the model to evaluate an entire text block at once, helping it correct mistakes during generation and enabling behaviors such as correctly closing complex markdown structures and generating code in near real time.
Performance and hardware requirements
DiffusionGemma is built as a 26B Mixture-of-Experts model that activates only 3.8 billion parameters during inference. When quantized, the model can fit within approximately 18GB of VRAM, allowing it to run on high-end consumer GPUs.
Google and NVIDIA say the model shifts text generation from a memory-bandwidth bottleneck to a compute-intensive workload, enabling better utilization of modern GPUs, Tensor Cores and CUDA optimizations. The companies describe this transition as moving from a sequential typewriter to a printing press that generates entire text blocks simultaneously.
Performance figures shared by Google and NVIDIA include:
- More than 1,000 tokens per second on a single NVIDIA H100 GPU
- More than 700 tokens per second on an NVIDIA GeForce RTX 5090
- Around 150 tokens per second on NVIDIA DGX Spark
- Up to 2,000 tokens per second on NVIDIA DGX Station
- Up to 4x faster text generation than comparable autoregressive models in local inference scenarios
Google notes that these gains are primarily designed for local and low-concurrency inference. In high-QPS cloud environments, autoregressive models can efficiently utilize hardware through batching, reducing the advantages of diffusion-based parallel decoding and potentially increasing serving costs. The throughput advantage is strongest at low-to-medium batch sizes on a single accelerator.
Fine-tuning and use cases
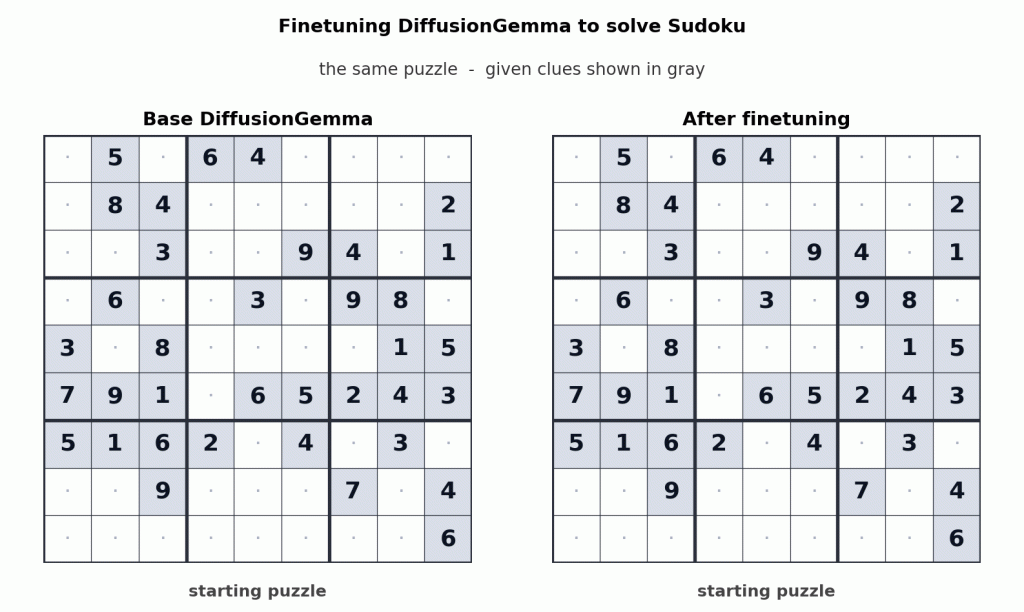
Google says DiffusionGemma can be fine-tuned for domain-specific workloads. As an example, Unsloth fine-tuned the model to solve Sudoku puzzles, a task that can be challenging for autoregressive models because predictions often depend on future tokens. DiffusionGemma’s bi-directional attention makes these types of workloads easier to handle.
The company expects the model to be useful for interactive chat, local AI assistants, agentic loops, on-device assistants that can plan and act, rapid content iteration, inline editing and other latency-sensitive AI applications.

While DiffusionGemma prioritizes speed and parallel generation, Google notes that its overall output quality remains lower than standard Gemma 4 models. For applications that require the highest quality production outputs, the company recommends using standard Gemma 4 models instead.
NVIDIA optimization and platform support
NVIDIA has optimized DiffusionGemma across its hardware ecosystem, including GeForce RTX GPUs, RTX PRO workstations, DGX Spark systems and DGX Station platforms. The company says the model can run entirely on supported RTX and DGX systems without relying on cloud inference or per-token API costs.
Supported platforms include:
- NVIDIA DGX Spark: Powered by the NVIDIA GB10 Grace Blackwell Superchip with 128GB of unified memory for local AI development, prototyping, fine-tuning and agent workflows.
- NVIDIA RTX PRO 6000: Designed for developers, researchers and AI professionals running low-latency local AI applications.
- NVIDIA DGX Station: Delivers up to 2,000 tokens per second and features 748GB of coherent memory for advanced local AI workloads.
- GeForce RTX GPUs: Optimized for consumer hardware, with official llama.cpp support expected in a future update.
Google says it worked closely with NVIDIA to optimize the model across consumer and enterprise hardware. This includes support for quantized deployments on GeForce RTX 4090 and RTX 5090 GPUs, as well as Hopper and Blackwell systems using advanced NVFP4 (4-bit floating-point) kernels. Native NVFP4 support improves compute throughput while maintaining near-lossless accuracy.
Developer ecosystem and availability
DiffusionGemma is available now as experimental open weights under the Apache 2.0 license.
The model launches with day-zero support across multiple AI frameworks and developer tools.
Frameworks and serving tools
- Hugging Face Transformers
- vLLM
- MLX
- NVIDIA NIM
- Red Hat-integrated vLLM deployments
Fine-tuning tools
- Unsloth
- NVIDIA NeMo
- Hackable Diffusion, a modular JAX toolbox designed for composable experimentation
Documentation and resources
- DiffusionGemma Developer Guide
- A Visual Guide to DiffusionGemma
- Deployment playbooks for DGX Spark, RTX PRO and DGX Station
Ways to access DiffusionGemma
- Download open weights from Hugging Face
- Test the model through NVIDIA-hosted APIs
- Deploy locally on supported RTX and DGX hardware
- Access through NVIDIA NIM
- Use through Gemini Enterprise Agent Platform Model Garden
Google also notes that official llama.cpp support is planned for a future release.