
Ookla’s latest analysis of AI platform reliability, based on 3.72 million Downdetector user reports, shows that the AI risk surface has significantly expanded as AI systems become deeply embedded in enterprise and consumer workflows.
The report by Luke Kehoe, Lead Industry Analyst at Ookla, finds that AI tools are no longer limited to short conversational use cases. Platforms such as ChatGPT, Claude, Gemini, and Microsoft Copilot are now widely used for writing, coding, research, analytics, and customer support, while enterprises are increasingly integrating them into structured and agentic workflows.
As adoption scales, reliability has become more critical. Even short disruptions such as login failures, stalled prompts, or broken connectors can now interrupt active business processes rather than isolated tasks.
Study Scope and Methodology
Ookla analyzed 471 days of U.S. Downdetector data from January 1, 2025 to April 16, 2026 across:
- ChatGPT
- Claude
- Gemini
- Microsoft Copilot
- AWS
- Microsoft Azure
The dataset covers 3.72 million user-reported incidents. A high-signal disruption day is defined as a day when a service records more than 10× its median daily report volume across the study period.
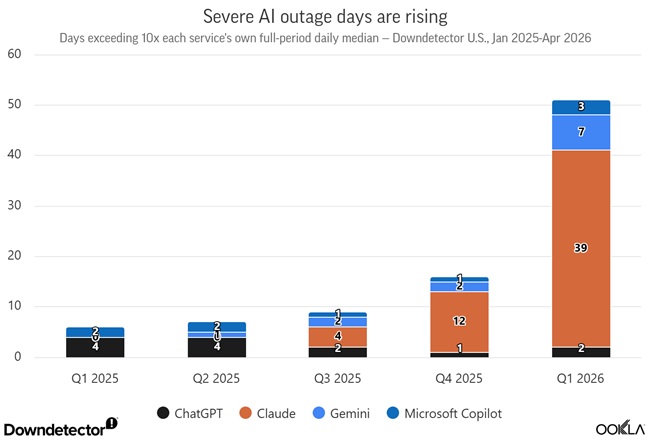
AI Disruptions Rise Sharply in Q1 2026
AI platform instability increased sharply across major services:
- Q1 2025: 6 high-signal disruption days
- Q4 2025: 16 high-signal disruption days
- Q1 2026: 51 high-signal disruption days
Breakdown of Q1 2026:
- Claude: 39 days
- Gemini: 7 days
- Copilot: 3 days
- ChatGPT: 2 days
This rise reflects increasing workload intensity and deeper integration of AI systems into daily workflows.
ChatGPT Shows High Peaks but Improving Stability
OpenAI’s ChatGPT recorded the largest individual disruption spikes:
- Dec 2, 2025: 67,567 reports
- Feb 4, 2026: 55,039 reports
- Jul 16, 2025: 51,420 reports
- Jun 10, 2025: 44,517 reports
- Feb 6, 2025: 41,674 reports
Despite these spikes, the baseline trend shows improvement:
- Median monthly reports fell from 2,157 (Apr 2025) to 1,166 (Apr 2026)
This indicates improving stability even as usage scaled significantly.
Usage context:
- 900M+ weekly ChatGPT users (early 2026)
- 4M+ weekly Codex users
- 10× Codex usage growth (Aug–Oct 2025)
Claude Emerges as the Most Volatile Platform
Anthropic’s Claude shows the most pronounced volatility pattern in the dataset.
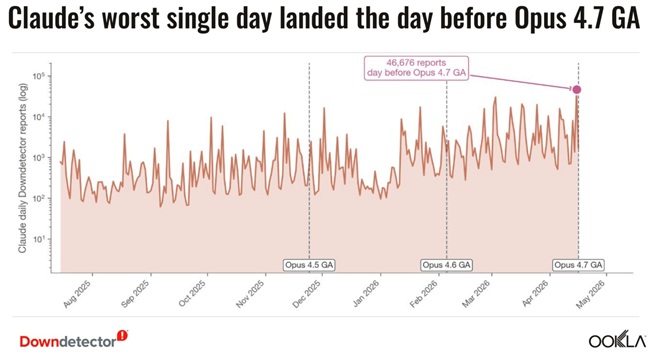
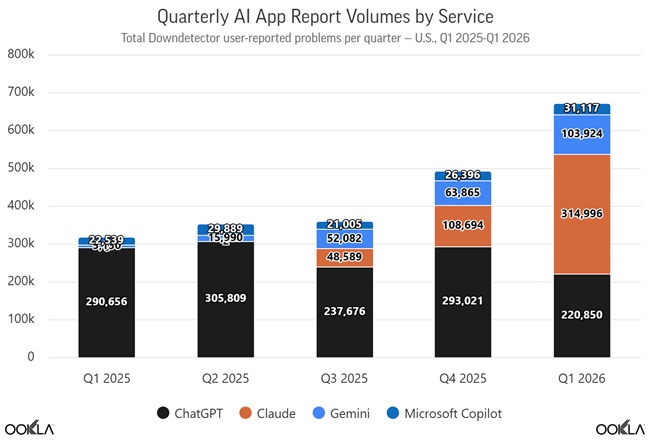
Report growth:
- Q3 2025: 48,589 reports
- Q4 2025: 108,694 reports
- Q1 2026: 314,996 reports
High-signal disruption days:
- Q3 2025: 4 days
- Q4 2025: 12 days
- Q1 2026: 39 days
Claude accounted for 192,773 reports in March 2026, nearly three times February levels.
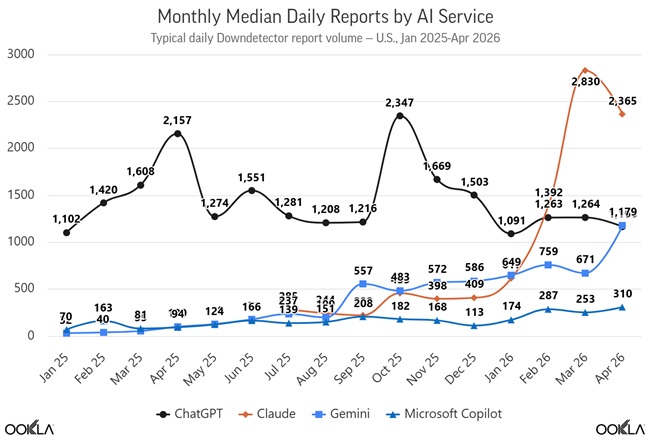
Key patterns include:
- Strong correlation between usage growth and spikes
- Demand surges and model release cycles influencing stability
- April 15, 2026 peak: 46,676 reports (before Opus 4.7 release)
Anthropic’s scaling in revenue and compute capacity also contributed to increased workload intensity across the platform.
Gemini and Copilot Show Distinct Reliability Patterns
Google Gemini
Gemini shows a steady rise in disruption signals:
- Q1 2025: 0 high-signal days
- Q1 2026: 7 high-signal days
Usage growth context:
- 750M+ users (Q4 2025)
- 900M+ users (May 2026)
Largest spike:
- Feb 13, 2026: 14,417 reports (ahead of Gemini 3.1 Pro announcement)
Microsoft Copilot
Copilot shows a distinct enterprise-driven pattern:
- Peak: June 4, 2025 → 12,028 reports
- Strong weekend drop-offs reflecting business usage
- Six co-spike events alongside OpenAI services
Copilot reflects deeper integration into Microsoft’s productivity and identity systems, where failures may originate across multiple layers beyond the model itself.
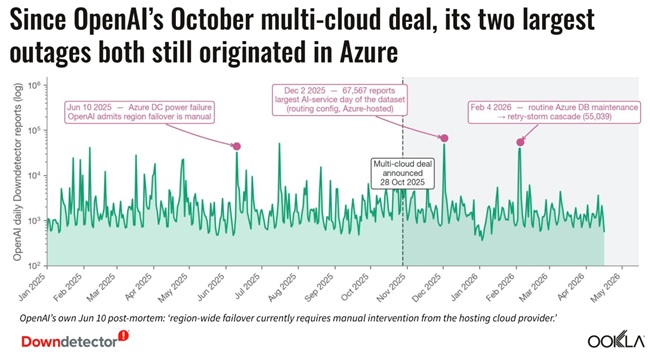
Hyperscaler Layer Remains a Critical Dependency
Cloud infrastructure continues to play a major role in AI reliability outcomes.
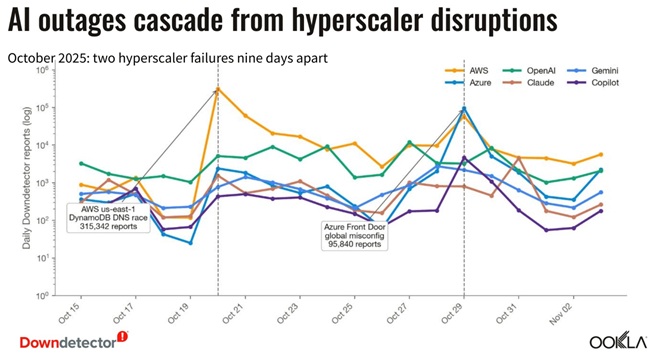
AWS incident:
- Oct 20, 2025: 315,342 reports
- Cause: DNS race condition in DynamoDB system
- Impact: EC2 and load balancing disruption
Azure incident:
- Oct 29, 2025: 95,840 reports
- Cause: Front Door routing failure
- Impact: global traffic routing disruption
These incidents highlight how infrastructure-layer failures can cascade into AI service disruption even when models are unaffected.
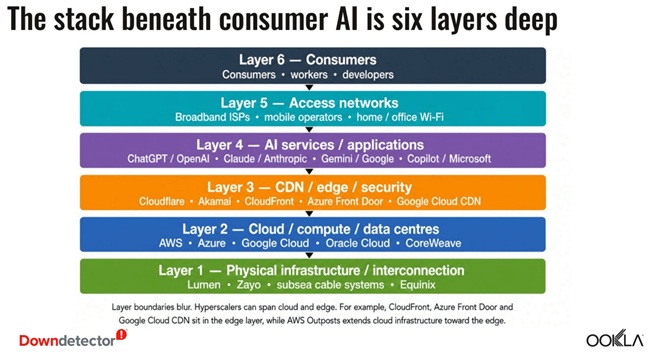
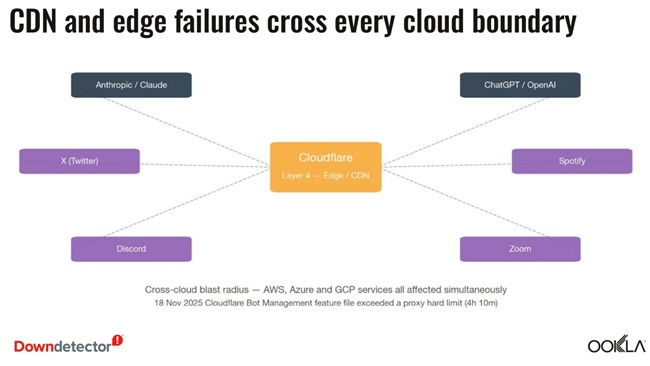
AI Reliability Now Spans Multiple System Layers
AI platforms now operate across interconnected layers:
- Product layer (user interface)
- Orchestration layer (routing, login, retries, model selection)
- Hyperscaler layer (compute, storage, networking)
- Edge layer (DNS, authentication, traffic routing)
A single user-facing issue such as a failed prompt or login loop can originate anywhere in this stack, making root-cause analysis significantly more complex.
AI Failure Surface Extends Beyond Chat Interfaces
Reliability issues are increasingly visible beyond chatbot downtime and now include:
- API outages
- File upload failures
- Workspace and connector issues
- Model-specific errors
- Authentication disruptions
Examples include:
- OpenAI Responses API rollback incident (May 2025)
- Claude model-specific disruptions across multiple model variants
Outlook
The findings indicate that AI reliability is shifting from simple uptime measurement to a multi-layer infrastructure dependency model. AI platforms are increasingly operating as core digital infrastructure, where reliability depends on stacked systems spanning model serving, orchestration layers, and underlying cloud infrastructure.
Key trends include:
- AI platforms becoming core operational infrastructure across industries
- Reliability depending on interconnected systems, including models, cloud, and orchestration layers
- Agentic workflows increasing dependency depth and amplifying failure impact
- Hyperscaler incidents remaining critical upstream risk factors
- Future disruptions potentially originating from any layer of the AI stack
Overall, AI reliability is no longer defined solely by model availability. It now reflects a broader system of interdependent infrastructure layers, where failures can originate anywhere in the stack but appear uniformly at the application level.