
At Google Cloud Next, Google announced its eighth-generation Tensor Processing Units (TPUs), introducing two purpose-built architectures: TPU 8t and TPU 8i. These chips are designed to support large-scale AI workloads, from model training and development to high-volume inference and agent-based systems.
The new generation builds on over a decade of TPU development and continues Google’s approach of co-designing silicon, networking, and software to improve efficiency and performance. TPUs have already powered foundation models such as Gemini.
Built for the agentic AI era
AI systems are moving toward agent-based workflows that require reasoning, multi-step execution, and continuous learning loops. These workloads demand infrastructure capable of handling long context windows, complex logic, and high concurrency.
To address this, TPU 8t and TPU 8i were developed in collaboration with Google DeepMind. The platforms are designed to support both large-scale training and real-time reasoning workloads, including emerging world models such as Genie 3 that simulate environments for agent learning.
Two architectures with different roles
Instead of a single general-purpose design, Google has introduced two specialized TPU systems:
- TPU 8t for large-scale training and pre-training
- TPU 8i for inference, sampling, and reasoning
Both chips can run a range of workloads, but this separation allows each to deliver better efficiency for its target use case.
TPU 8t: Designed for large-scale training
TPU 8t focuses on accelerating model training by combining high compute throughput, memory capacity, and interconnect bandwidth. It is built to shorten training cycles while maintaining high system utilization.
A single TPU 8t superpod scales to large configurations, allowing complex models to operate within a unified compute and memory environment.
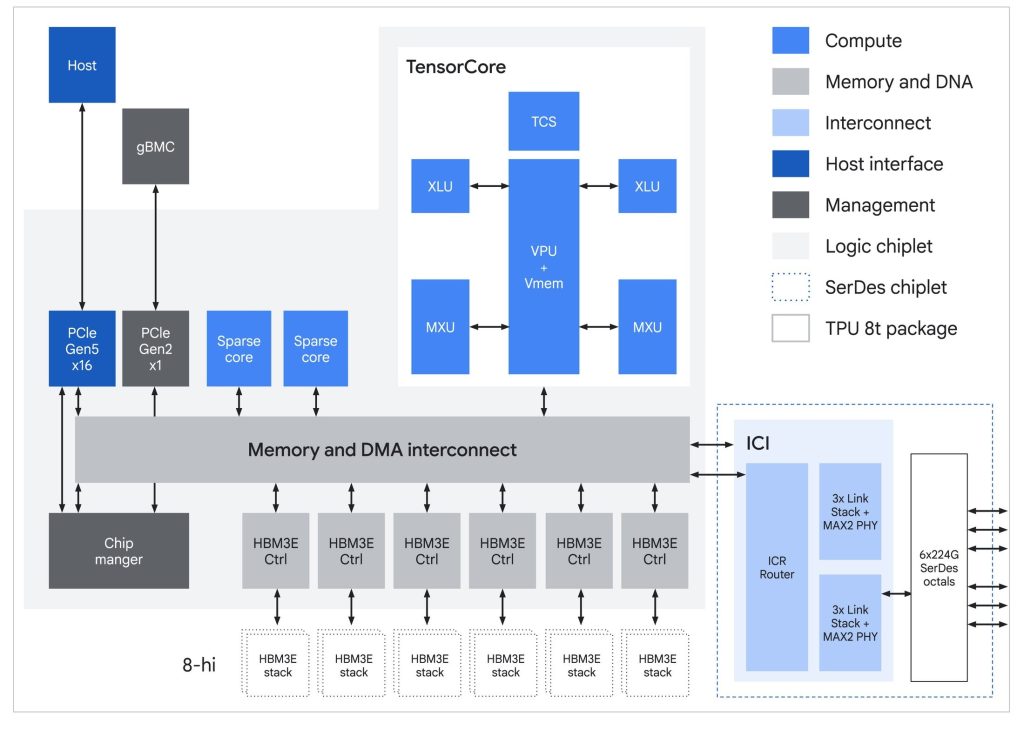
Key capabilities
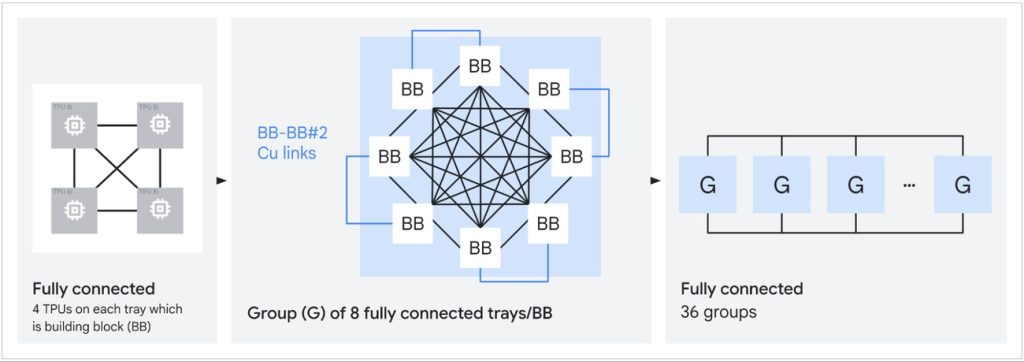
- Massive scale: Up to 9,600 chips per superpod with 2PB shared high-bandwidth memory and 121 ExaFlops compute
- Bandwidth improvements: 2x inter-chip bandwidth and up to 4x data center network bandwidth through Virgo Network
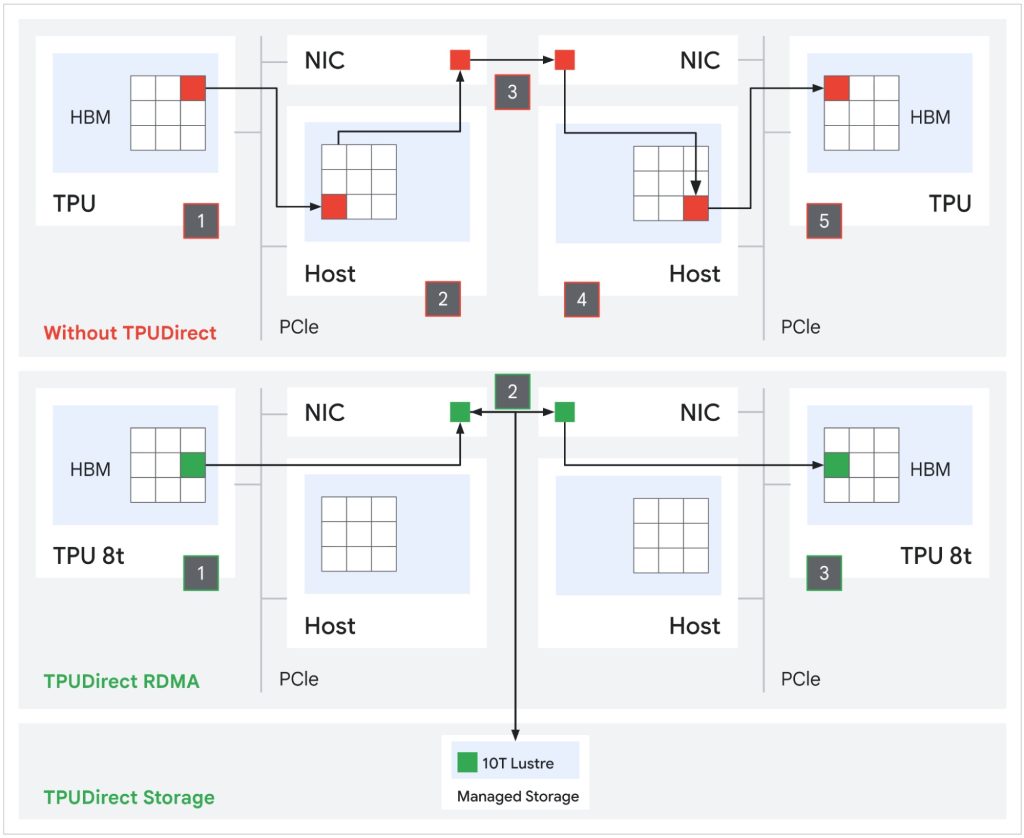
- Faster data access: TPUDirect RDMA and TPU Direct Storage enable direct transfers, delivering up to 10x faster storage access
- Near-linear scaling: Supports scaling to more than 1 million chips using JAX and Pathways
- High utilization: Designed to achieve over 97% goodput through system-level reliability and optimization
The architecture also introduces SparseCore for embedding workloads and native FP4 precision to improve compute efficiency and reduce memory overhead.
TPU 8i: Built for inference and reasoning
TPU 8i is optimized for latency-sensitive workloads, particularly those involving multiple AI agents operating concurrently. It is designed to reduce delays in communication, synchronization, and memory access.
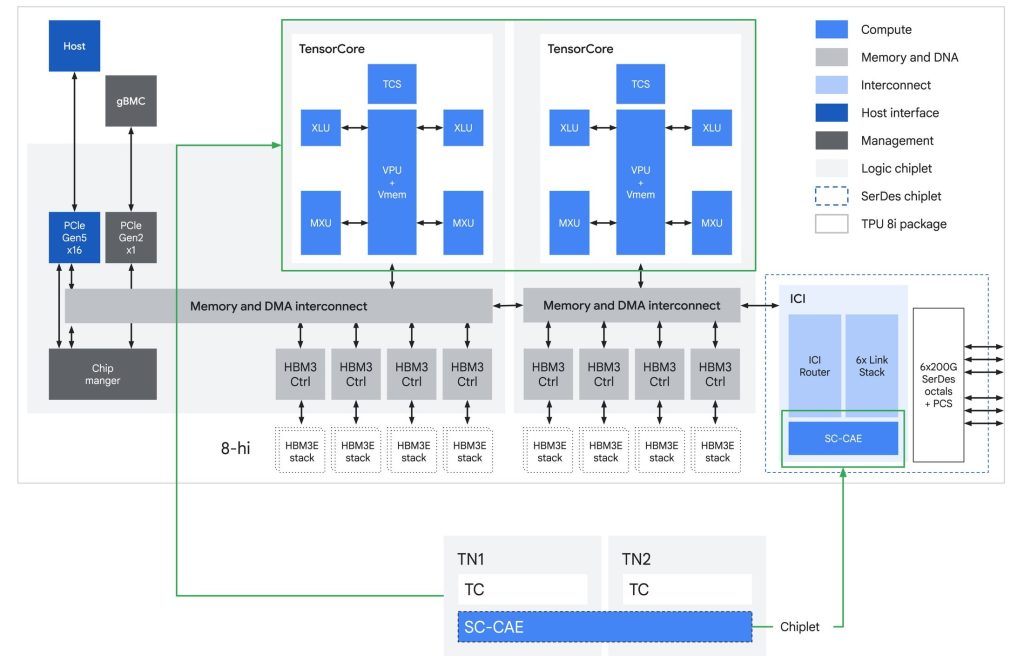
Key innovations
- Higher memory bandwidth: 288GB HBM and 384MB on-chip SRAM, around 3x more SRAM than the previous generation
- Lower latency: Collectives Acceleration Engine (CAE) reduces synchronization latency by up to 5x
- Optimized networking: Boardfly topology reduces network diameter by over 50%, improving communication efficiency
- Axion CPUs: Custom Arm-based CPUs with NUMA architecture improve system-level performance and data handling
These changes enable TPU 8i to deliver up to 80% better performance-per-dollar compared to the previous generation, especially for reasoning and Mixture-of-Experts (MoE) models.
Network and system design advancements
Google has introduced workload-specific networking architectures for both TPU variants.
- Virgo Network (TPU 8t): A scale-out network with high-radix switches and a multi-planar design to reduce latency and increase bandwidth
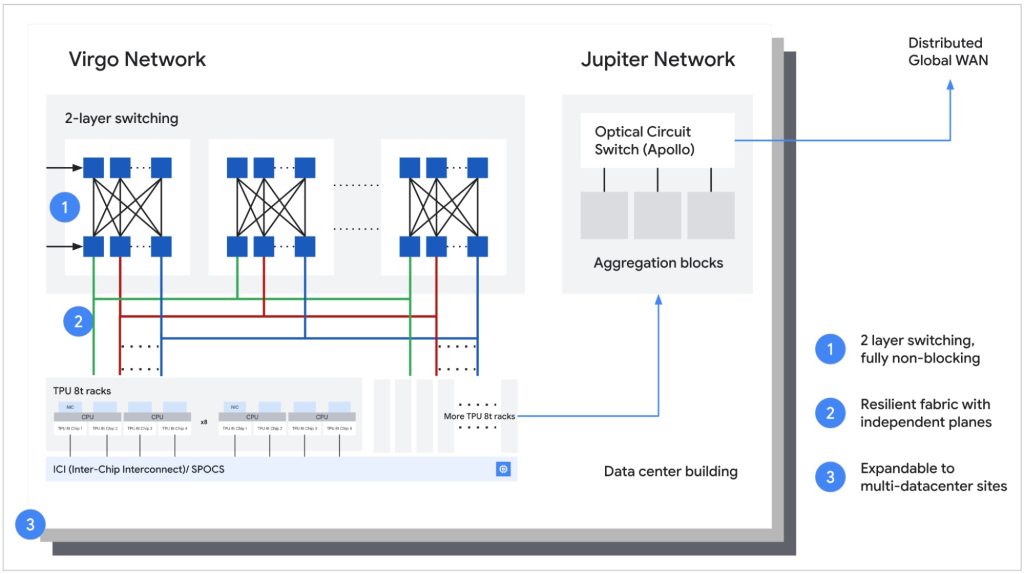
- Boardfly topology (TPU 8i): A hierarchical network that reduces communication hops from 16 in a 3D torus to 7, improving latency for distributed workloads
These changes are aimed at maintaining efficiency as clusters scale to large sizes.
Software and developer ecosystem
TPU 8t and TPU 8i support widely used frameworks, enabling developers to deploy models without major changes.
Supported stack
- JAX, PyTorch, Keras
- vLLM, SGLang, MaxText
- XLA and Pathways for scaling and orchestration
Additional support includes native PyTorch (preview), Pallas and Mosaic for kernel-level optimization, and bare metal access without virtualization overhead.
Power efficiency and data center integration
Efficiency is a key focus for large-scale AI systems. TPU 8t and TPU 8i deliver up to 2x better performance-per-watt compared to the previous generation.
Google has optimized efficiency across the stack:
- Integration of compute and networking to reduce data transfer overhead
- Dynamic power management based on workload demand
- Fourth-generation liquid cooling for higher density deployments

The company states its data centers now deliver six times more compute per unit of electricity compared to five years ago.
TPU 8t vs TPU 8i: Quick comparison
| Feature | TPU 8t | TPU 8i |
|---|---|---|
| Primary use | Training / Pre-training | Inference / Reasoning |
| Network topology | 3D Torus + Virgo | Boardfly |
| HBM capacity | 216 GB | 288 GB |
| On-chip SRAM | 128 MB | 384 MB |
| Peak FP4 performance | 12.6 PFLOPs | 10.1 PFLOPs |
| HBM bandwidth | 6,528 GB/s | 8,601 GB/s |
| Specialized unit | SparseCore | CAE |
| CPU host | Axion Arm-based | Axion Arm-based |
AI Hypercomputer integration
Both TPU systems are part of Google Cloud’s AI Hypercomputer, which combines compute, storage, networking, and software into a unified platform. This setup is designed to support the full AI lifecycle, from training to deployment and large-scale inference.
Availability and industry adoption
Google said TPU 8t and TPU 8i will be generally available later this year through Google Cloud as part of its AI Hypercomputer platform.
The company also noted that organizations such as Citadel Securities are already using TPUs for advanced AI workloads, indicating early adoption in production environments.