
OpenAI on Thursday introduced GPT-5.2, the company’s most capable model series for professional knowledge work. The update follows continued adoption of ChatGPT in enterprises, where typical users report saving 40–60 minutes per day, and heavy users report more than 10 hours saved per week.
GPT-5.2
GPT-5.2 is designed to expand this productivity impact. The model improves at creating spreadsheets, generating presentations, writing code, interpreting images, handling long documents, using tools, and managing complex multi-step workflows. The release was developed in collaboration with NVIDIA and Microsoft, using Azure data centers powered by H100, H200, and GB200-NVL72 GPUs.
GPT-5.2 in ChatGPT
Users should experience more structured and consistent behaviour across the three GPT-5.2 experiences:
- GPT-5.2 Instant: Faster responses with improvements in info-seeking, technical writing, translations, and step-by-step guidance.
- GPT-5.2 Thinking: Designed for deeper work involving coding, long-document summarization, math and logic, and multi-stage tasks.
- GPT-5.2 Pro: Intended for difficult questions where higher-quality reasoning is worth longer response times.
Model Naming
ChatGPT
- ChatGPT-5.2 Instant
- ChatGPT-5.2 Thinking
- ChatGPT-5.2 Pro
API
- gpt-5.2-chat-latest
- gpt-5.2
- gpt-5.2-pro
OpenAI reminds users to double-check outputs for critical tasks.
Performance
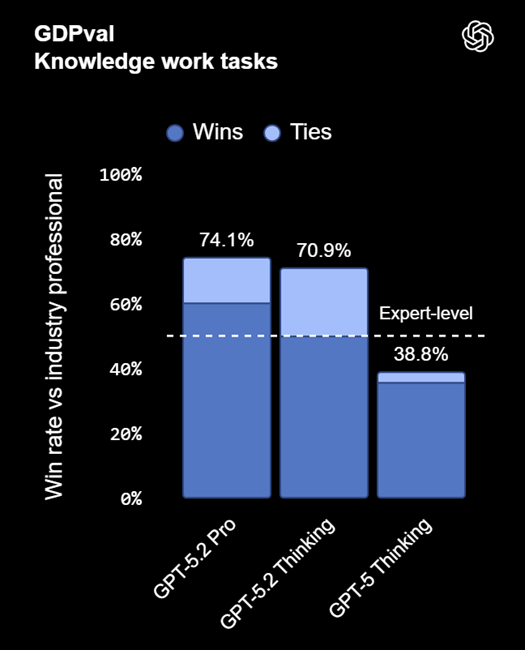
GPT-5.2 sets new state-of-the-art results across multiple evaluations, including GDPval, where it surpasses industry professionals on well-specified knowledge tasks spanning 44 occupations.
Partners such as Notion, Box, Shopify, Harvey, and Zoom reported stronger long-horizon reasoning and tool-calling performance. Databricks, Hex, and Triple Whale noted gains in agent-driven data science and document analysis. Cognition, Warp, Charlie Labs, JetBrains, and Augment Code observed higher agentic coding performance.
Economically Valuable Tasks
GPT-5.2 Thinking achieves OpenAI’s highest performance yet on GDPval, becoming the company’s first model to match or exceed human expert levels. It ties or outperforms top professionals in 70.9% of comparisons. The model generated GDPval outputs more than 11× faster and at under 1% of the cost of expert professionals, based on historical metrics.
A GDPval evaluator described one output as “a noticeable leap in output quality… done by a professional company with staff,” while noting minor errors remained.
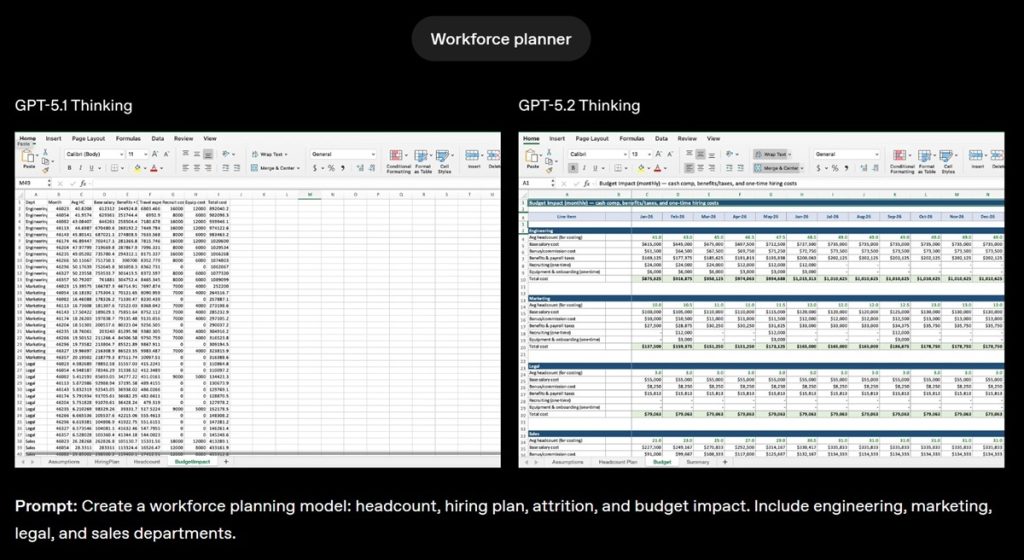
On OpenAI’s internal benchmark for junior investment-banking modeling tasks—such as building three-statement models or leveraged buyout models—the model’s average score rose from 59.1% to 68.4%, a 9.3% improvement over GPT-5.1.
Coding
GPT-5.2 Thinking sets a new high score of 55.6% on SWE-Bench Pro, which evaluates real-world engineering tasks across four programming languages. On the SWE-Bench Verified benchmark, it achieves 80%, the highest yet from OpenAI.
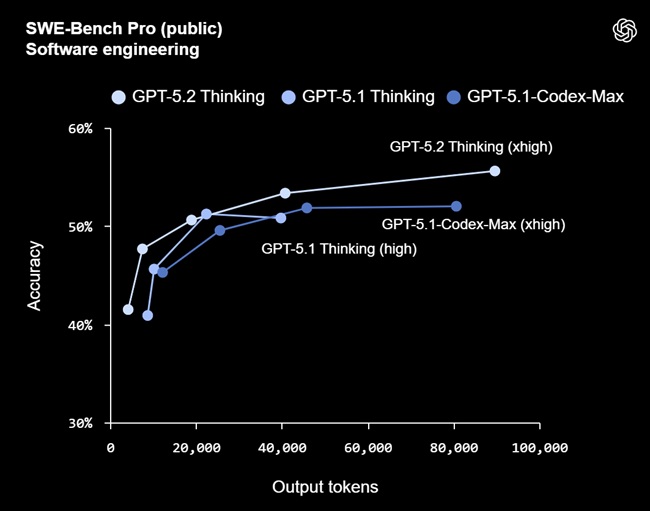
The model shows stronger performance in debugging, feature implementation, code refactoring, and end-to-end fixes. Early testers also reported better results in front-end development, including complex UI work and 3D interface tasks.
Factuality
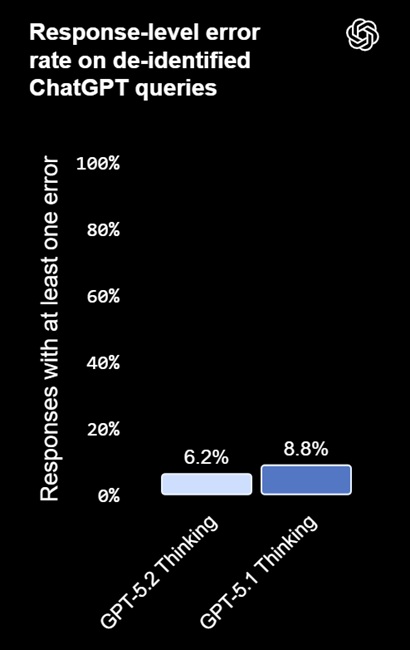
GPT-5.2 Thinking reduces hallucination rates by 30% compared to GPT-5.1 Thinking, based on de-identified ChatGPT queries. This improves reliability for research, writing, analysis, and decision support.
Long-Context Reasoning
GPT-5.2 Thinking delivers new state-of-the-art results on MRCRv2, designed to test a model’s ability to integrate information across long documents.
It reaches near-perfect accuracy on the 4-needle MRCR task at up to 256k tokens, improving coherence and accuracy for workflows involving reports, contracts, research papers, transcripts, and multi-file projects.
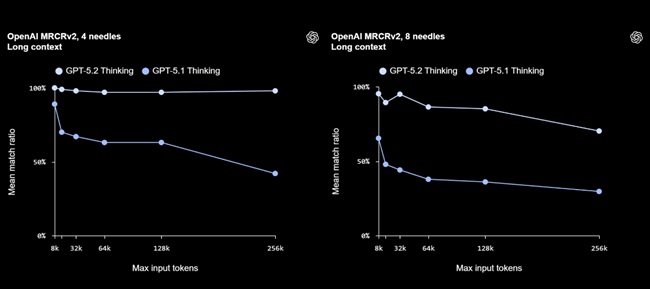
The model also supports OpenAI’s new Responses /compact endpoint, extending effective context for tool-heavy and long-running tasks.
Vision
GPT-5.2 Thinking halves error rates on chart reasoning and software-interface understanding compared to earlier models. It shows improved awareness of spatial relationships and element positioning in images, enabling more accurate interpretation of dashboards, diagrams, product screenshots, and technical visuals.
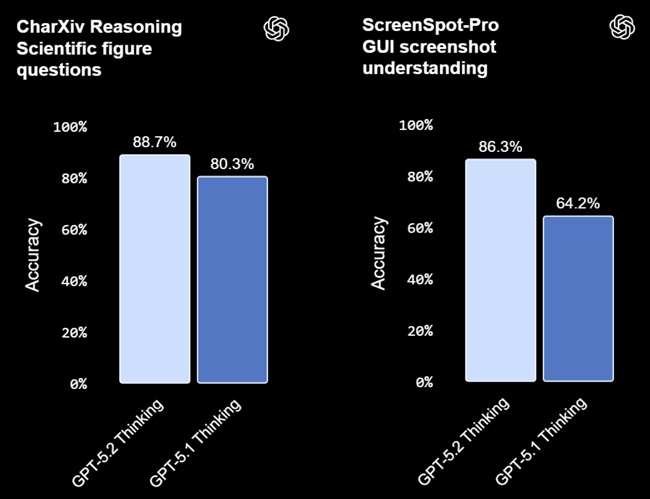
OpenAI notes that in bounding-box tests on low-quality images, GPT-5.2 correctly identified more components with better spatial grouping than GPT-5.1, though both models still made errors.

Tool Calling
GPT-5.2 Thinking reaches 98.7% on Tau2-bench Telecom, demonstrating stronger reliability across long, multi-turn tool-use workflows. It also performs significantly better with reasoning.effort=’none’, improving latency-sensitive use cases.
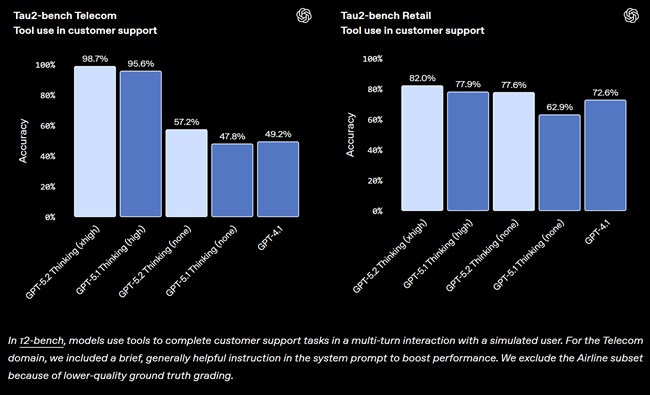
In multi-agent setups such as customer-support scenarios, GPT-5.2 coordinated complete workflows—covering rebooking, special-assistance seating, and compensation—where GPT-5.1 produced partial results.
Science and Mathematics
- GPT-5.2 Pro and GPT-5.2 Thinking are positioned as OpenAI’s strongest scientific models to date.
- GPQA Diamond: GPT-5.2 Pro scores 93.2%, with GPT-5.2 Thinking at 92.4%.
- FrontierMath (Tier 1–3): GPT-5.2 Thinking solves 40.3% of expert-level problems, setting a new state of the art.
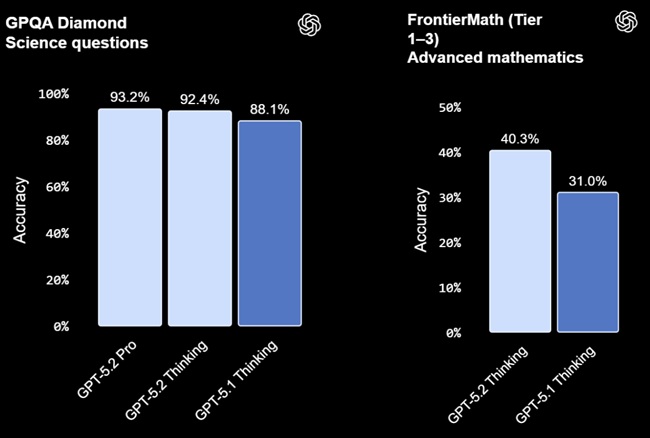
OpenAI notes that researchers recently used GPT-5.2 Pro in a controlled setting to explore an open question in statistical learning theory. The model proposed a proof later verified by the authors and reviewed by external experts.
ARC-AGI
GPT-5.2 Pro is the first model to surpass 90% on ARC-AGI-1 (Verified), improving from last year’s o3-preview score of 87% while reducing the cost of achieving that performance by roughly 390×.
On ARC-AGI-2 (Verified), GPT-5.2 Thinking achieves 52.9%, while GPT-5.2 Pro reaches 54.2%, reflecting stronger multi-step reasoning and abstract problem-solving.
Safety
GPT-5.2 builds on safety improvements introduced with GPT-5, targeting more reliable responses in sensitive conversations involving self-harm, mental-health distress, and emotional over-reliance on AI. Both GPT-5.2 Instant and Thinking show fewer undesirable outputs than GPT-5.1 models.
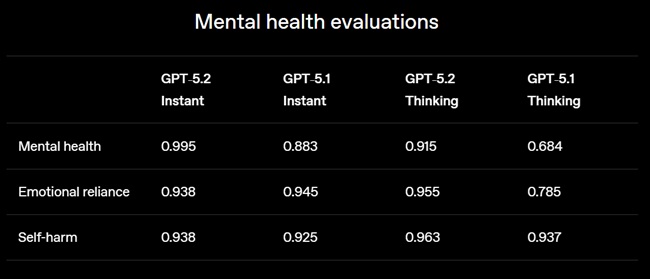
OpenAI is also rolling out an age-prediction model to automatically apply content protections for users under 18, alongside existing parental-control systems. The company notes ongoing work on issues such as over-refusals as it continues improving safety and reliability.
Availability and Pricing
GPT-5.2 (Instant, Thinking, and Pro) begins rolling out today in ChatGPT for Plus, Pro, Go, Business, and Enterprise users. Deployment will be gradual. GPT-5.1 will remain available for three months under legacy models before being sunset for paid users.
In the API:
- gpt-5.2 (Thinking) is available through the Responses and Chat Completions APIs.
- gpt-5.2-chat-latest corresponds to GPT-5.2 Instant.
- gpt-5.2-pro is available for GPT-5.2 Pro.
GPT-5.2 Pro and Thinking now support the new xhigh reasoning-effort level. Spreadsheet and presentation tools require GPT-5.2 Thinking or Pro on Plus, Pro, Business, or Enterprise plans.
Token Pricing (API)
- GPT-5.2: $1.75 per 1M input tokens; $14 per 1M output tokens
- 90% discount applied to cached input tokens
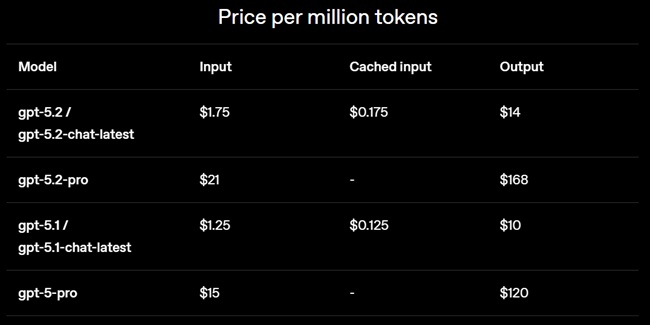
OpenAI says GPT-5.2’s higher per-token cost is offset by greater token efficiency on multi-agent evaluations. There are no current deprecation plans for GPT-5.1, GPT-5, or GPT-4.1 in the API. A Codex-optimized GPT-5.2 variant is expected soon.