
OpenAI has released GPT-4, its latest AI model, which has achieved human-level performance on various professional and academic benchmarks.
Previous releases include ChatGPT and Whisper APIs, while GPT-3.5 scored in the bottom 10% on a simulated bar exam, GPT-4 scored in the top 10%, thanks to 6 months of improvement and alignment. GPT-4 has also achieved great results on factuality, steerability, and staying within guardrails.
Announcing GPT-4, a large multimodal model, with our best-ever results on capabilities and alignment: https://t.co/TwLFssyALF pic.twitter.com/lYWwPjZbSg
— OpenAI (@OpenAI) March 14, 2023
GPT-4 Capabilities
GPT-4 has been proven to be more reliable, creative and able to handle nuanced instructions when compared to GPT-3.5. To verify this, the firm tested a variety of benchmarks, including;
GPT-4: More reliable, creative and able to handle nuanced instructions
Testing: Variety of benchmarks, simulating exams designed for humans
Source: Most recent publicly-available tests, 2022–2023 practice exams
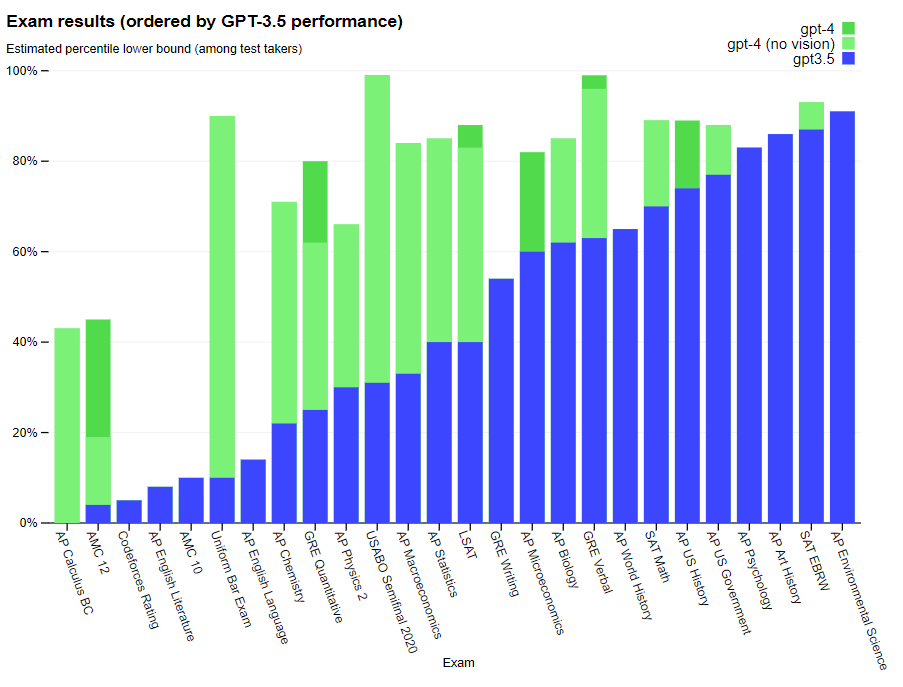
English-language performance
The firm has been using GPT-4 internally with great success, across functions like support, sales, content moderation, and programming.
To get an initial sense of capability in other languages, they translated the MMLU benchmark into a variety of languages, and found that GPT-4 outperformed the English-language performance of GPT-3.5 and other LLMs for 24 out of 26 languages tested, including low-resource languages like Latvian, Welsh, and Swahili.
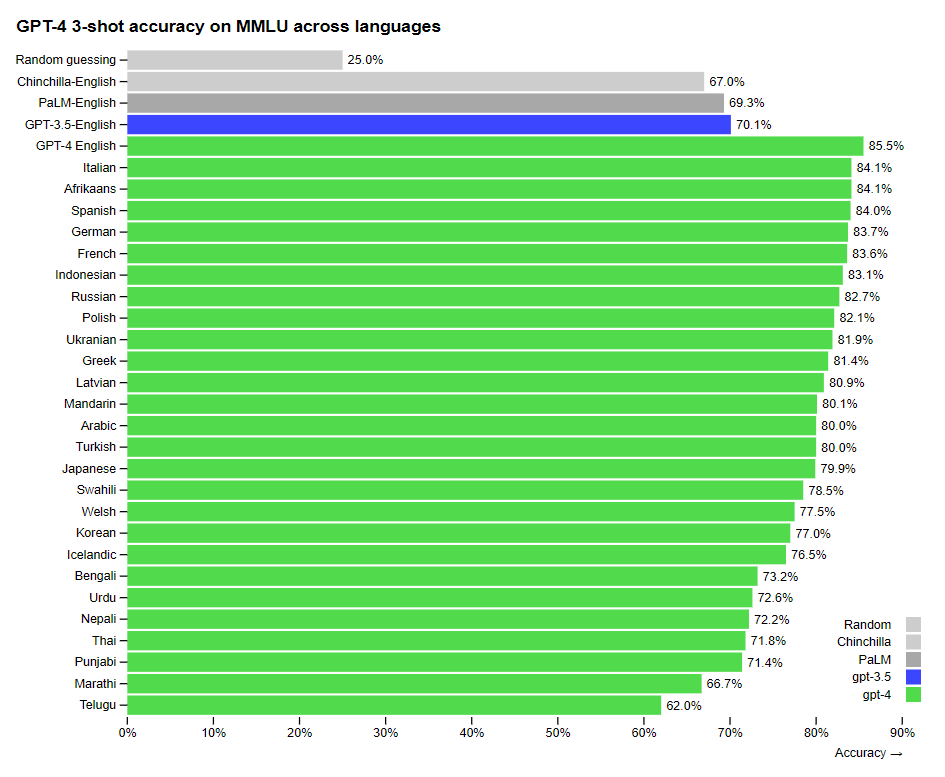
This marks the beginning of the second phase in their alignment strategy, using GPT-4 to assist humans in evaluating AI outputs.
Visual inputs
GPT-4 can take a prompt of text and images, allowing users to assign any vision or language task. It produces text outputs from input of both text and images, and works across many domains like documents with text and photos, diagrams and screenshots.
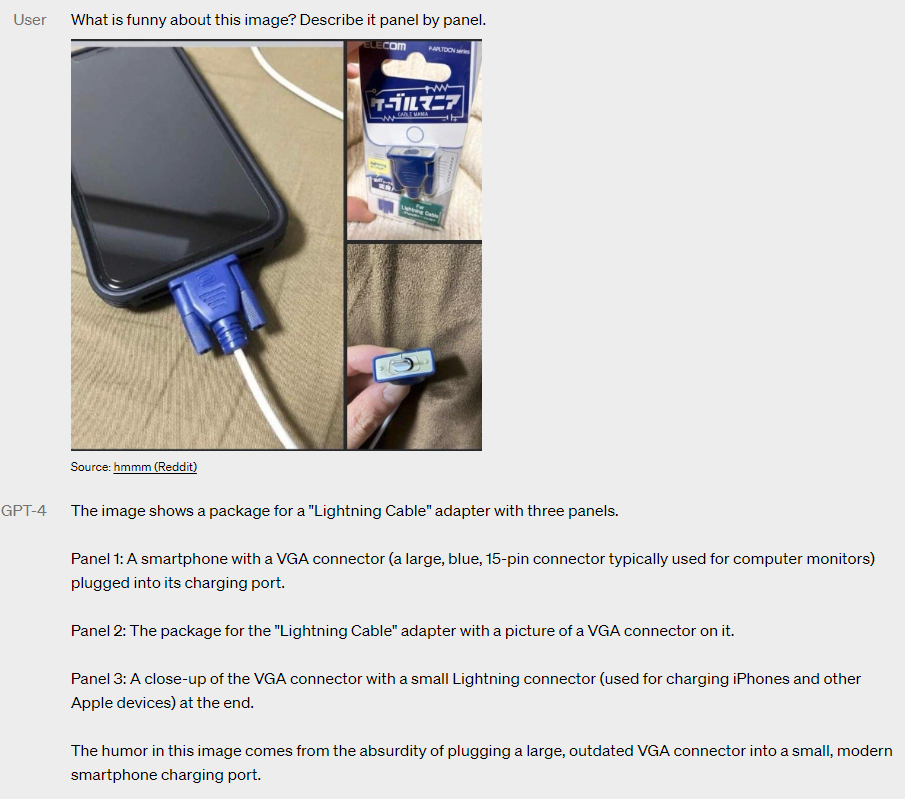
Plus, it can use the same text-only language models for few-shot and chain-of-thought prompting. Image inputs are still in the research preview stage and not publicly available yet.
Steerability
The firm has been hard at work on their AI plan, allowing developers (and soon users) to customize the experience through system messages. These messages let users define boundaries to control the AI’s style and task. They are aware that the adherence to the boundaries isn’t perfect, and are open to feedback.
Limitations
GPT-4 still has limitations, such as hallucinating facts and making reasoning errors, so it should be used carefully, even in high-stakes contexts.
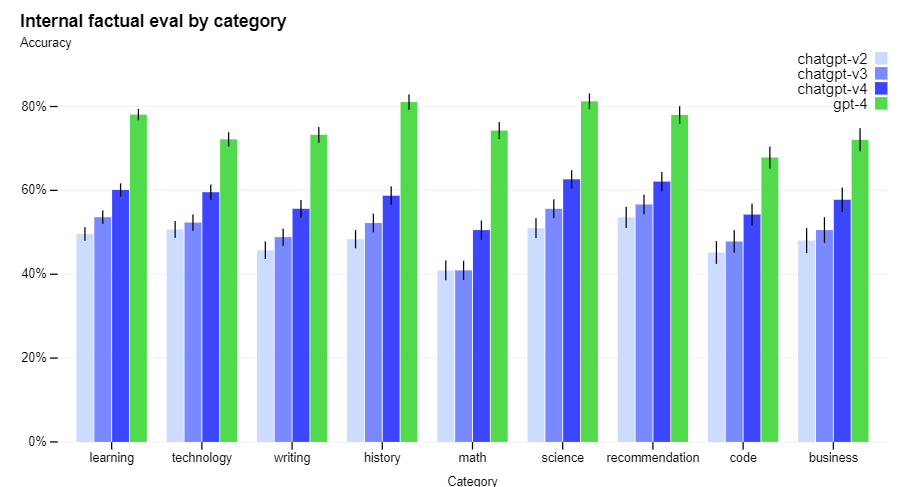
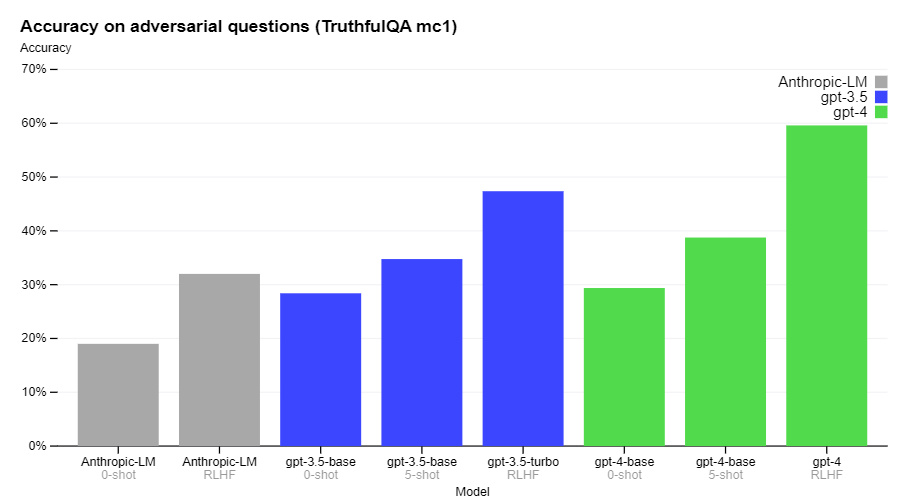
- Adversarial factuality: GPT-4 scores 40% higher than GPT-3.5 on our internal adversarial factuality evaluations, and is significantly better at separating fact from incorrect statements.
- Bias: The model can have biases, but progress has been made, and more work needs to be done.
- Errors: GPT-4 can make simple reasoning errors, lack knowledge of recent events, and be overly gullible. It can also be confidently wrong in predictions, losing its calibration after post-training.
Risks & mitigations
The firm is taking great strides to ensure GPT-4 is safe, with iterative measures, expert engagement, and model-level interventions. These have improved upon GPT-3.5, but there are still limitations and risks, so they are also collaborating with external researchers to understand the potential impacts of GPT-4 and other AI systems.
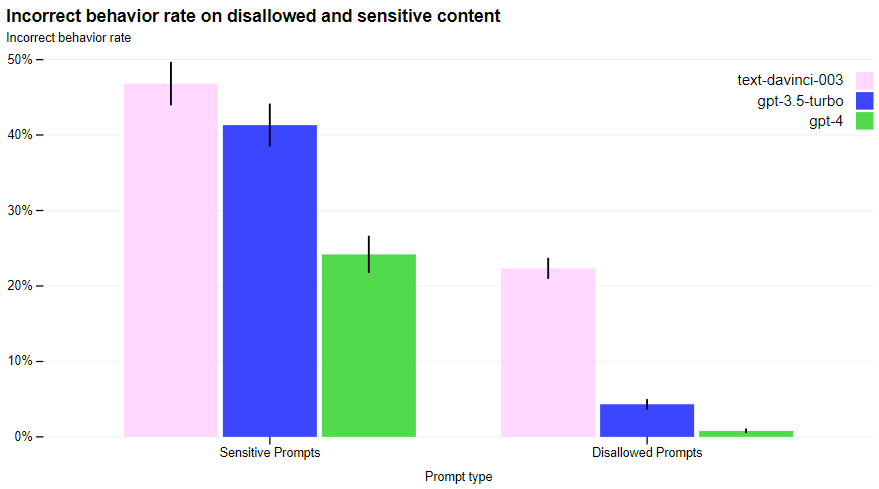
Iterations: The firm has been iterating on GPT-4 to make it safer and more aligned from the start, by selecting data, making safety improvements, and enforcing policies.
Experts: Over 50 experts from various fields have been engaged to test the model and identify potential risks.
Safety Reward Signal: GPT-4 has incorporated a safety reward signal during training to reduce harmful outputs.
Improvements: Mitigations have improved GPT-4 safety properties compared to GPT-3.5.
Limitations: Model-level interventions increase the difficulty of eliciting bad behavior but it is still possible.
Impacts: The firm is collaborating with external researchers to understand and assess potential impacts, as well as building evaluations for dangerous capabilities in future systems.
Training process
The GPT-4 base model was pre-trained using web-scale data, which includes a vast range of ideologies and ideas. To make sure it meets user intent within predefined guardrails, we fine-tune the model’s behavior using reinforcement learning with human feedback.
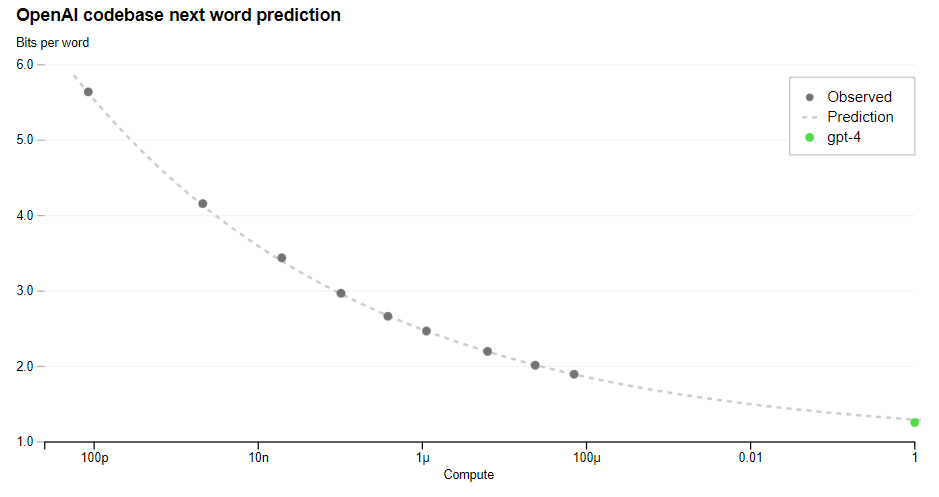
Predictable scaling
The GPT-4 project has developed infrastructure and optimization that scale predictably. To prove this, they accurately predicted in advance the loss on an internal codebase, extrapolating from models with 10,000x less compute. They are now expanding their efforts, developing methods to predict more interpretable metrics.
OpenAI Evals
The firm has open-sourced OpenAI Evals, a software framework for creating and running benchmarks for evaluating models like GPT-4. It can help guide model development, track performance and measure accuracy.
To make it easier to use, the firm has also included templates for writing new classes and implementing existing benchmarks. They invite everyone to use Evals to test their models and submit the most interesting examples!
- Evals helps identify shortcomings and prevent regressions.
- It’s compatible with implementing existing benchmarks.
- They’ve created a logic puzzles eval which contains ten prompts where GPT-4 fails.
ChatGPT Plus
ChatGPT Plus subscribers get GPT-4 access on chat.openai.com, with a usage cap adjusted according to demand and system performance.
The company is expecting to be capacity-constrained, but will scale up and optimize with time. They may introduce a new subscription level for higher-volume GPT-4 usage, and also plan to offer free GPT-4 queries for those without a subscription.
The new Bing runs on OpenAI’s GPT-4
Microsoft’s Corporate Vice President & Consumer Chief Marketing Officer, Yusuf Mehdi, has confirmed that Bing is now running on OpenAI’s GPT-4, a powerful model customized for searching. If you’ve used the new Bing preview in the past five weeks, you’ve already experienced it.
As OpenAI makes further updates, Bing will continue to benefit from them.
Announcing the updates, OpenAI posted that
We look forward to GPT-4 becoming a valuable tool in improving people’s lives by powering many applications. There’s still a lot of work to do, and we look forward to improving this model through the collective efforts of the community building on top of, exploring, and contributing to the model.