Google is getting closer to its aim of building an AI language model that works for 1,000 languages. On Monday, it gave more info about the Universal Speech Model (USM). They consider it a “critical first step” in achieving their plans.
November last year, Google unveiled the 1,000 Languages Initiative; a bold pledge to develop an ML model that caters to the 1,000 most spoken languages in the world, enabling billions of people to experience inclusion.
Google – Universal Speech Model (USM)
Google introduces Universal Speech Model (USM), a breakthrough in supporting 1,000 languages. USM is a family of speech models, leveraging 12 million hours of speech and 28 billion sentences of text from 300+ languages. It enables automatic speech recognition (ASR) for widely-spoken languages like English and Mandarin, as well as under-resourced languages like Amharic, Cebuano, Assamese, and Azerbaijani.
Google USM: Scaling Automatic Speech Recognition beyond 100 Languages explains how pre-training the encoder of the model on a large unlabeled multilingual dataset and fine-tuning on a smaller set of labeled data can recognize under-represented languages. Their model training process is effective in adapting to new languages and data.
Self-supervised learning: Google’s approach to speech recognition combines self-supervised learning with fine-tuning. USM uses the encoder-decoder architecture, where the decoder can be CTC, RNN-T, or LAS. The encoder employs the Conformer, a convolution-augmented utilizes a Conformer block with attention, feed-forward, and convolutional modules.
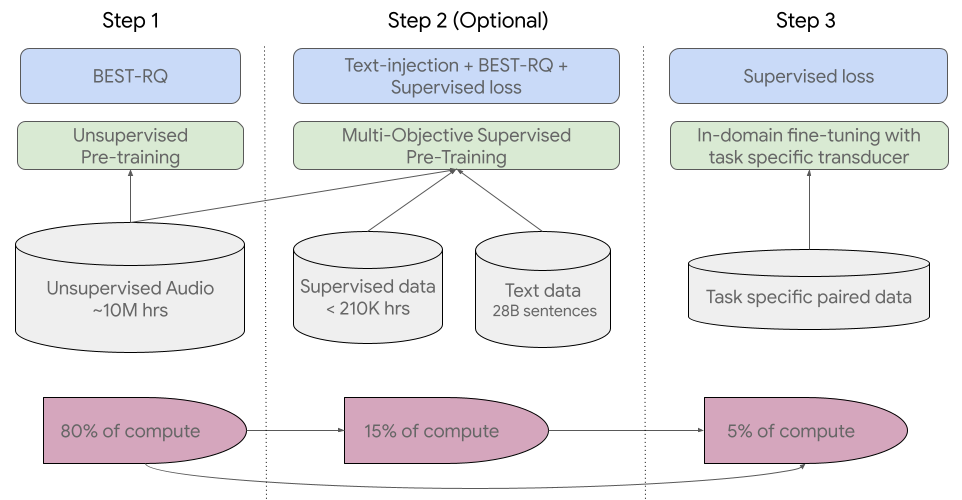
This block takes the log-mel spectrogram of the speech signal as input, performs convolutional sub-sampling, and ultimately produces the final embeddings.
Pre-trained encoder enables 300+ languages
Google’s encoder utilizes over 300 languages through pre-training and has been tested on YouTube Caption’s multilingual speech data. This data consists of 73 languages, each with an average of fewer than 3,000 hours of data. Despite the limited amount of supervised data, the model has achieved a WER of less than 30% on average with all 73 languages.
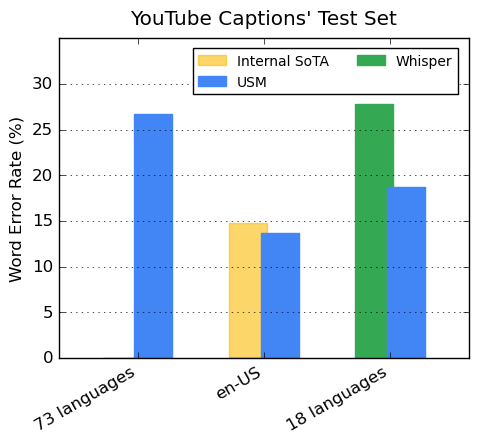
Generalization to downstream ASR tasks
Google reported that their model had lower WER on CORAAL (African American Vernacular English), SpeechStew (en-US), and FLEURS (102 languages) datasets compared to Whisper.
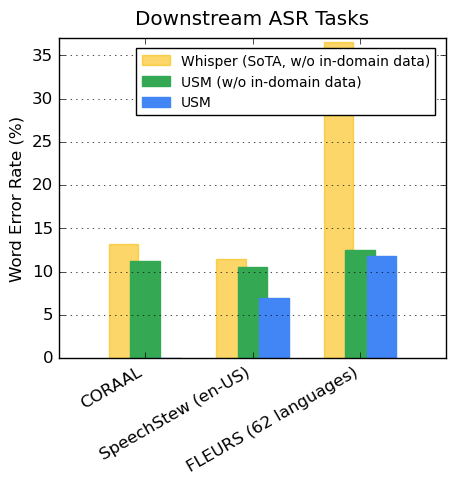
Their model showed lower WER with and without training on in-domain data. The comparison on FLEURS was done on the subset of languages (62) supported by the Whisper model.
Automatic speech translation (AST)
Google states that their fine-tuned USM model on the CoVoST dataset has achieved state-of-the-art quality with minimal supervision. To evaluate its performance, the CoVoST dataset was divided into high, medium and low resource availability segments, and the BLEU score (higher is better) was calculated for each.
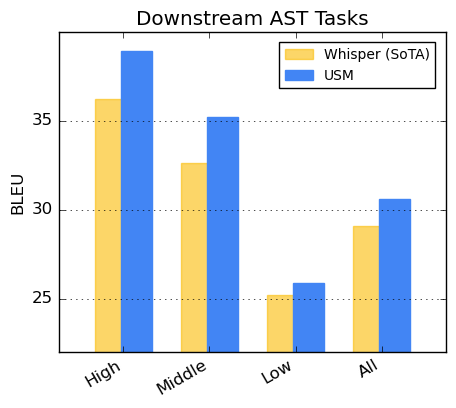
Google Translate has recently been upgraded with AI features such as contextual translation and more. USM outperformed Whisper in all segments, as displayed below.
Marching Toward 1,000 languages
Google is striving hard to fulfill its mission of organizing the world’s information and making it universally accessible via its USM development.
Google plans to use the base model architecture and training pipeline of USM as a foundation to expand speech modeling to the next 1000 languages. To learn more – click here.