
DeepSeek has introduced the DeepSeek-V4 series, a new generation of Mixture-of-Experts (MoE) language models focused on long-context processing, reasoning, and agent-based tasks. The release includes DeepSeek-V4-Pro and DeepSeek-V4-Flash, both supporting up to one million tokens of context, which is now set as the default across DeepSeek services.
The models combine architectural updates, training changes, and system-level optimizations to reduce compute and memory usage while scaling performance across reasoning, coding, and long-context workloads.

DeepSeek-V4-Pro
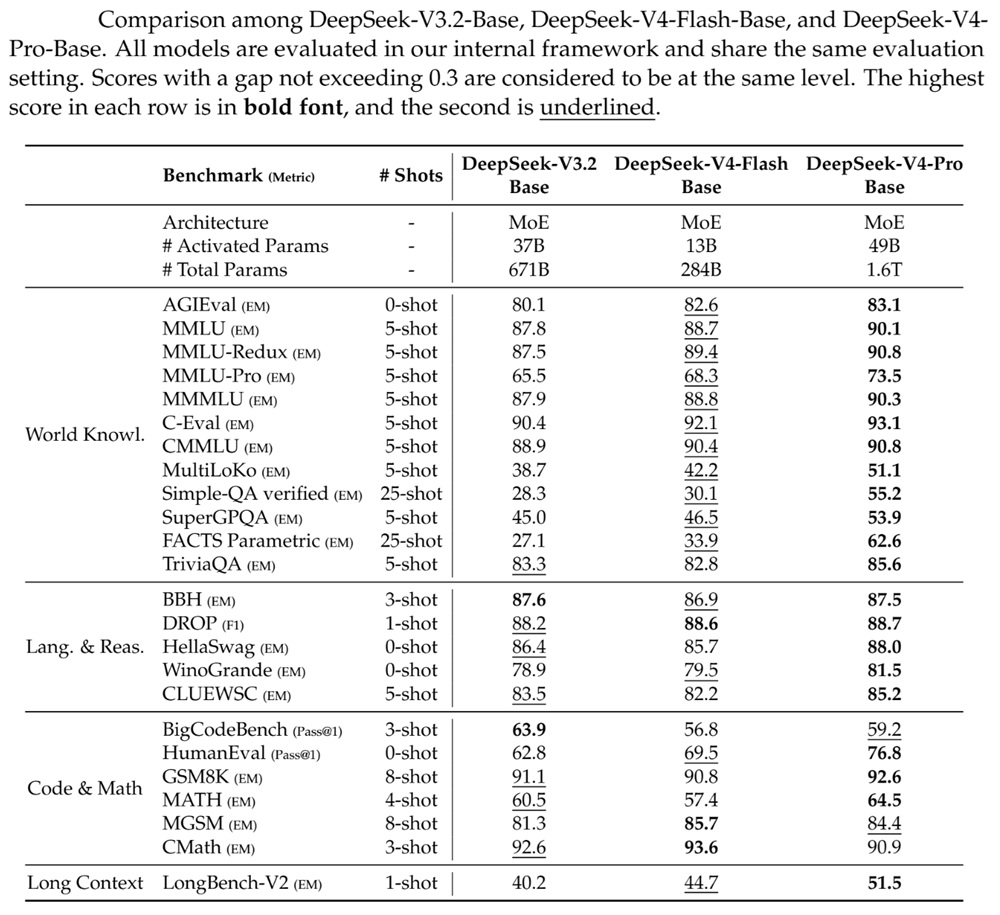
DeepSeek-V4-Pro is the larger model in the series and is designed for high-complexity tasks involving reasoning, coding, and extended context processing. It follows a Mixture-of-Experts architecture, where only a subset of parameters is active during inference.
Key details:
- 1.6 trillion total parameters with 49 billion active
- Context length of up to 1M tokens
- Trained on more than 33 trillion tokens
- Includes a higher reasoning configuration referred to as Pro-Max mode
The model is trained using a multi-stage pipeline that includes pre-training, supervised fine-tuning, reinforcement learning, and on-policy distillation.
DeepSeek-V4-Flash
DeepSeek-V4-Flash is a smaller and more compute-efficient variant designed to reduce latency and cost while maintaining similar capabilities across many tasks.
Core specifications:
- 284 billion total parameters with 13 billion active
- Context length of up to 1M tokens
- Trained on more than 32 trillion tokens
It is designed to deliver comparable reasoning performance under higher compute settings, while offering faster responses in standard use.
Key Features and Architecture
DeepSeek-V4 introduces a redesigned attention system and multiple architectural updates aimed at improving efficiency in long-context scenarios.
The attention system combines:
- Compressed Sparse Attention (CSA)
- Heavily Compressed Attention (HCA)
This hybrid approach reduces the number of key-value entries processed during attention through token-level compression, while maintaining relevant context using sparse top-k selection. A sliding window attention branch is also used to preserve local token relationships, alongside an attention sink mechanism that adjusts normalization behavior.
The model structure includes updates to improve scaling and stability:
- Manifold-Constrained Hyper-Connections (mHC) for stable residual mapping
- Hash-based routing in early layers of the MoE system
- Continued use of Multi-Token Prediction (MTP) for training efficiency
Additional efficiency optimizations include:
- Use of FP4 and FP8 precision to reduce compute and memory usage
- Hybrid KV cache storage with compression and mixed precision
- On-disk KV cache handling for long-context inference
Infrastructure and Training
The DeepSeek-V4 series includes system-level improvements that support large-scale training and efficient inference.
Key updates include:
- Fine-grained expert parallelism to overlap communication and computation
- Fused kernel execution using TileLang-based implementations
- Deterministic and batch-invariant kernels for consistent outputs
- Contextual parallelism for handling long-context workloads
- Quantization-aware training to improve efficiency
These changes allow the models to maintain performance while reducing resource usage across different deployment scenarios.
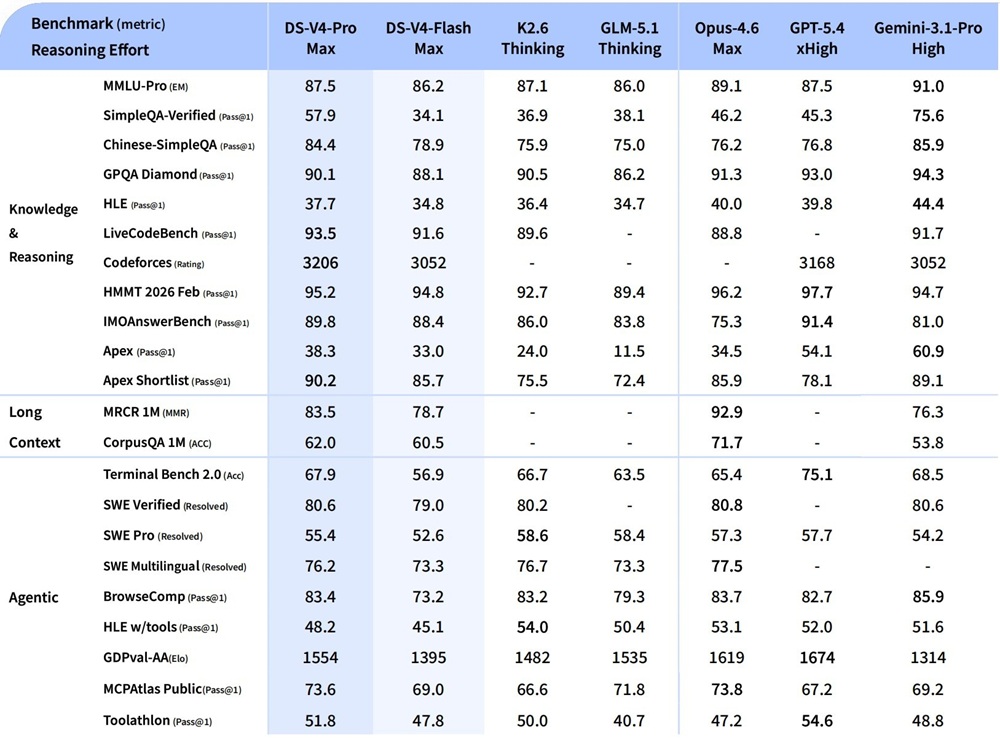
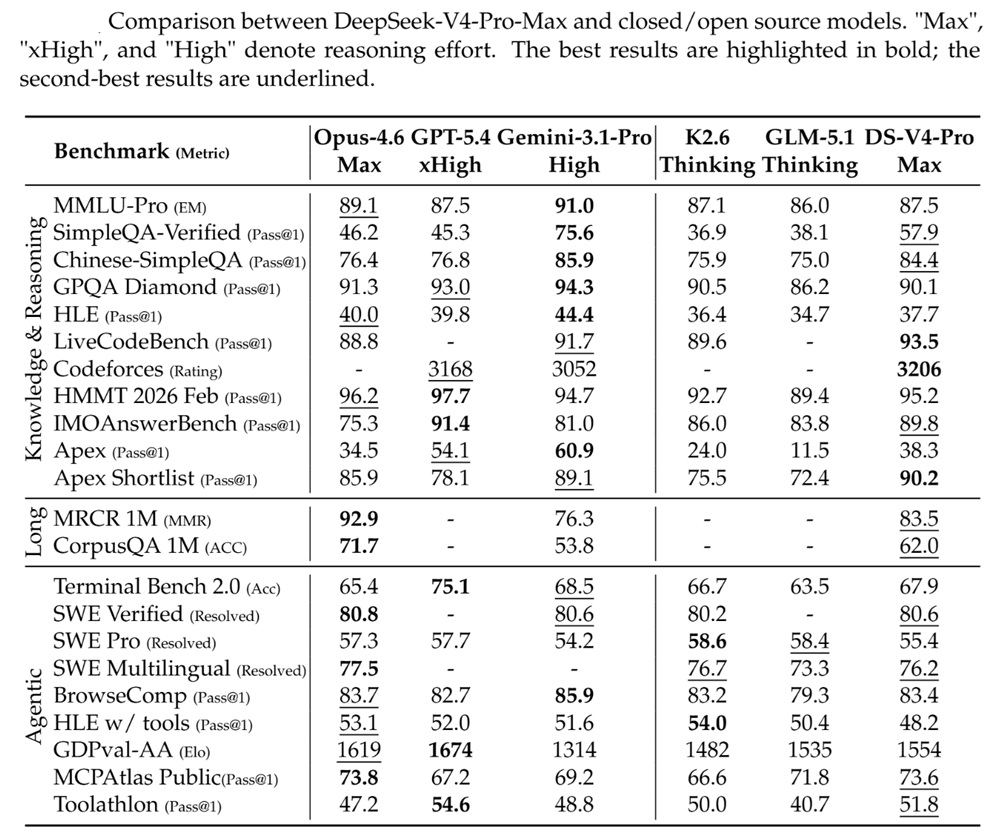
Performance and Benchmarks
DeepSeek-V4 shows improvements across reasoning, coding, and long-context evaluations based on internal and public benchmarks.
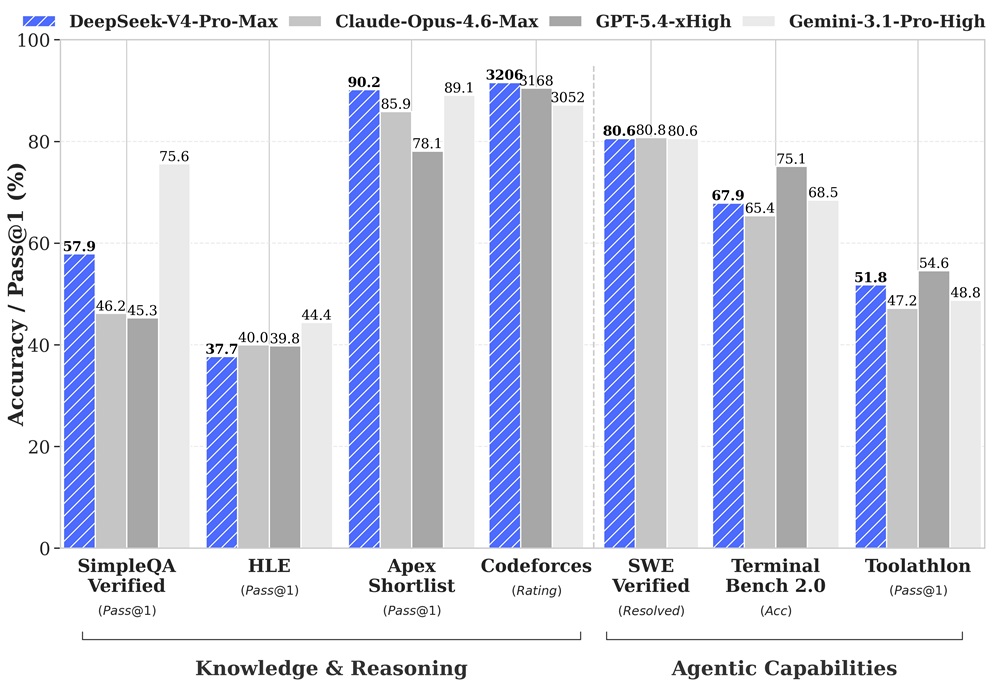
For knowledge and reasoning:
- Evaluated on SimpleQA, MMLU-Pro, GPQA, and HLE
- Improves over previous DeepSeek models
- Remains slightly behind some proprietary models in certain knowledge tasks
For coding and agent-related tasks:
- Evaluated on SWE benchmarks, Codeforces, Toolathlon, and TerminalBench
- Demonstrates competitive performance among open models
- Reported as leading among open models in agentic coding benchmarks
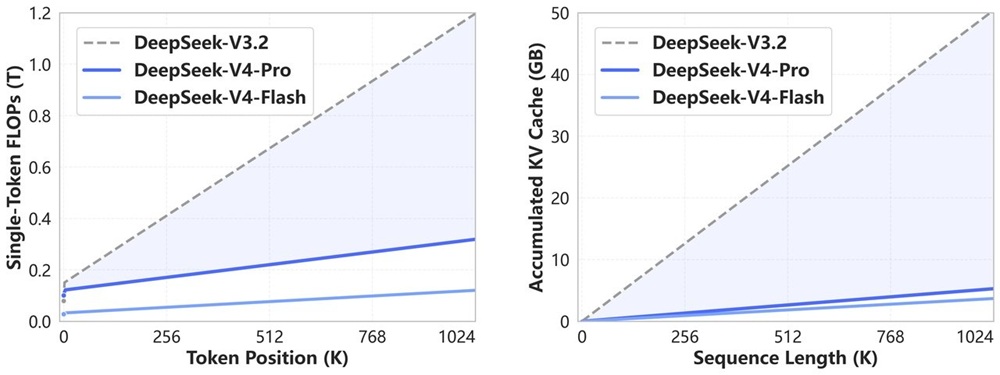
For long-context performance:
- Supports 1M token inputs in standard configuration
- Maintains performance across extended sequences
Efficiency improvements include:
- Around 27% of inference FLOPs compared to earlier versions (Pro)
- Around 10% KV cache usage compared to earlier versions (Pro)
- Further reductions in compute and memory usage for the Flash variant
Agent Capabilities
DeepSeek-V4 is designed to support agent-based workflows that involve multi-step reasoning and tool interaction.
The models integrate with systems such as:
- Claude Code
- OpenClaw
- OpenCode
They are also used internally for agent-oriented coding workflows and support structured execution pipelines involving multiple steps and tools.
Safety and Stability
The models include several mechanisms aimed at maintaining numerical stability and consistent behavior.
These include:
- Residual constraints through mHC to stabilize deep model training
- RMS normalization within attention mechanisms
- Deterministic kernel execution for reproducible outputs
- Batch-invariant computation to maintain consistency
- Controlled attention behavior for long-context scenarios
Availability
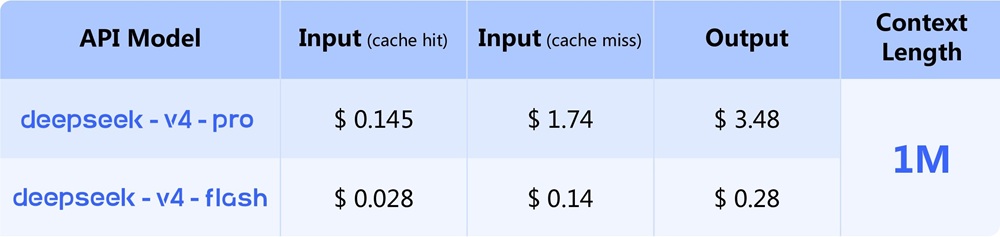
DeepSeek-V4 is available through web access and API, with support for standard developer integrations.
- Accessible via web interface and API
- Model checkpoints released publicly
The API supports:
- OpenAI ChatCompletions format
- Anthropic API format
Available model identifiers:
deepseek-v4-prodeepseek-v4-flash
Both models support:
- Thinking mode for extended reasoning
- Non-thinking mode for faster responses
DeepSeek has also confirmed that the following models will be retired:
deepseek-chatdeepseek-reasoner
These will become inaccessible after July 24, 2026 (UTC) and are currently routed to DeepSeek-V4 models.