
Meta is advancing its AI infrastructure with the Meta Training and Inference Accelerator (MTIA), a family of custom-built silicon chips designed for efficient AI workloads. First developed in 2023, MTIA now spans multiple generations, with four new chips — MTIA 300, 400, 450, and 500 — planned for deployment over the next two years to support ranking, recommendations, and Generative AI (GenAI) workloads.
Scaling AI Infrastructure with Custom Silicon
MTIA chips are deployed across Meta’s platforms for both organic content and advertising workloads. The chips form part of a full-stack solution optimized for the company’s AI tasks, achieving higher compute efficiency and cost-effectiveness compared with general-purpose hardware.

Meta uses a portfolio approach, combining internally developed MTIA chips with silicon from other industry providers to scale infrastructure capacity while keeping MTIA at the center of its strategy.
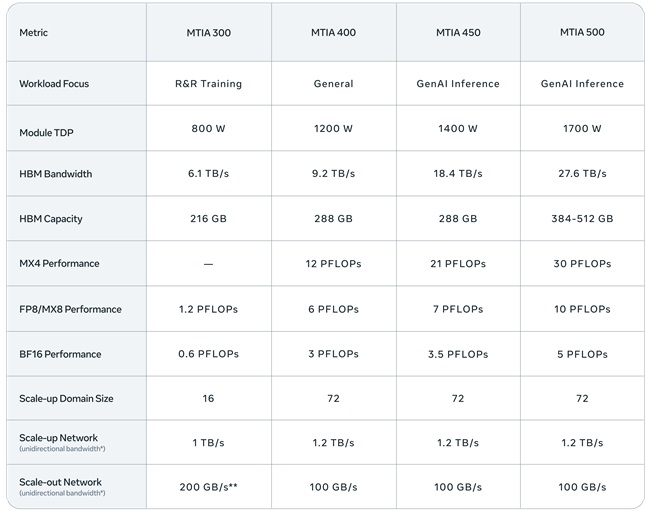
MTIA Generations and Deployment
-
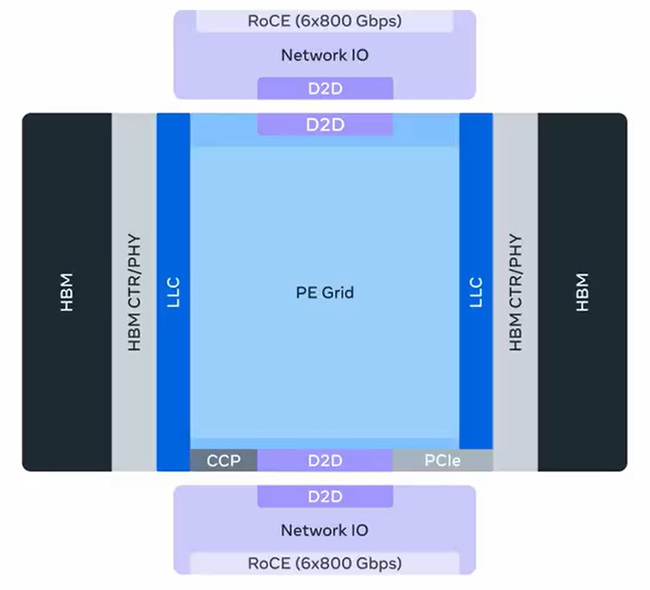
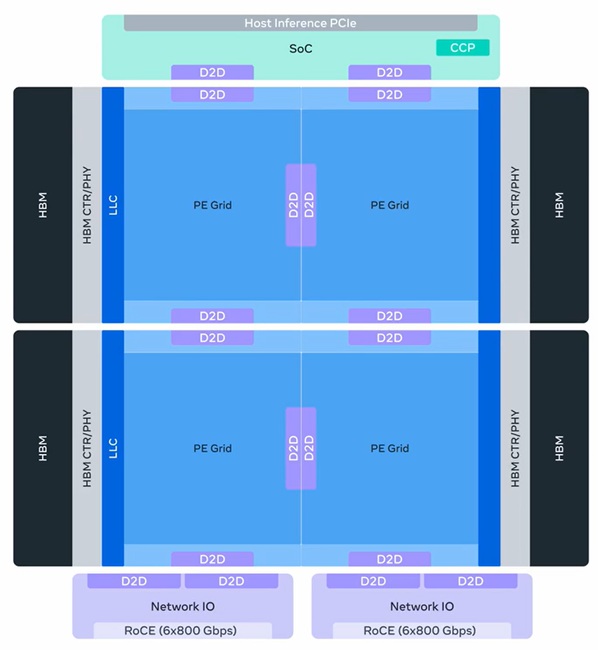
MTIA 300 – Optimized for ranking and recommendation (R&R) training, MTIA 300 is already in production. Its design includes one compute chiplet, two network chiplets, several high-bandwidth memory (HBM) stacks, and processing elements (PEs) with RISC-V vector cores, dot product engines, special function units, reduction engines, and DMA engines. MTIA 300 introduced low-latency communication and near-memory compute, forming a foundation for later GenAI chips.
-
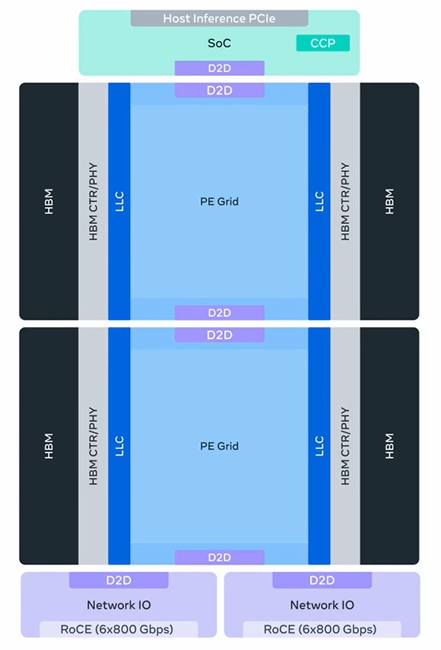
MTIA 400 – Evolved from MTIA 300 to support GenAI workloads while maintaining R&R capabilities. MTIA 400 delivers 400% higher FP8 FLOPS and 51% higher HBM bandwidth than MTIA 300, combining two compute chiplets for higher density. A rack-scale system with 72 MTIA 400 devices forms a scale-up domain with air-assisted liquid cooling (AALC) for rapid deployment in legacy data centers.
-
MTIA 450 – Optimized for GenAI inference, MTIA 450 doubles HBM bandwidth over MTIA 400, increases MX4 FLOPS by 75%, introduces hardware acceleration for attention and feed-forward networks, and supports mixed low-precision computation. Mass deployment is planned for early 2027.
-
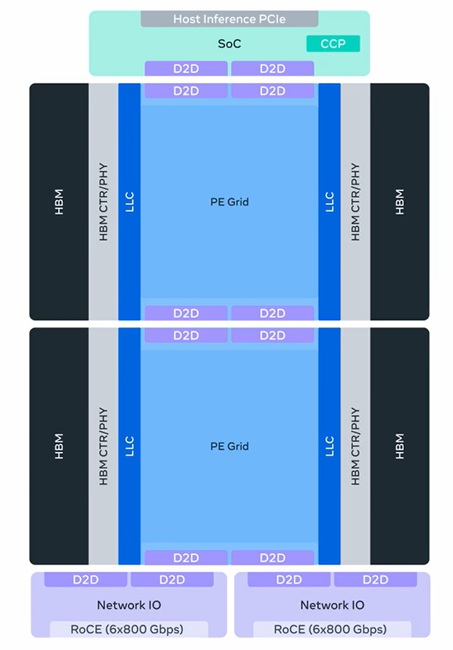
MTIA 500 – Further enhances GenAI inference performance with 50% higher HBM bandwidth, up to 80% higher HBM capacity, and 43% higher MX4 FLOPS compared with MTIA 450. MTIA 500 uses a modular 2×2 compute chiplet configuration with SoC and network chiplets and additional hardware acceleration for inference bottlenecks. Deployment is planned in 2027.
Performance Evolution – From MTIA 300 to 500, HBM bandwidth increases 4.5× and compute FLOPS rises 25×, demonstrating the benefits of Meta’s high-velocity development strategy.
MTIA Development Strategy
Meta’s MTIA strategy is built on three pillars:
- High-Velocity Iterative Development – Chips are released roughly every six months. Modular, reusable chiplets, chassis, racks, and network infrastructure allow faster adaptation to evolving AI workloads and new hardware technologies.
- Inference-First Optimization – MTIA 450 and 500 are designed primarily for GenAI inference, with backward compatibility for R&R training and inference, ensuring cost-efficient performance for anticipated workload growth.
- Frictionless Adoption – MTIA chips integrate natively with industry-standard software ecosystems including PyTorch, vLLM, Triton, and the Open Compute Project (OCP), enabling seamless deployment in data centers and compatibility with existing AI models without MTIA-specific rewrites.

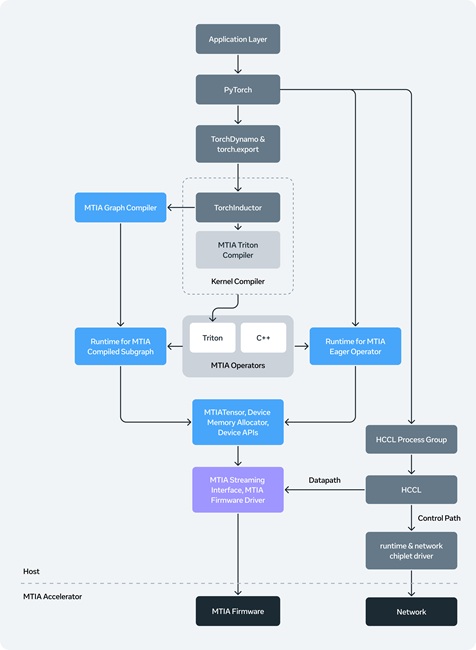
MTIA Software and Tools
The MTIA software stack is PyTorch-native and consistent across chip generations. Key capabilities include:
- Seamless Model Onboarding – Supports eager and graph modes, integrating with PyTorch 2.0 compilation pipelines via torch.compile and torch.export. Models can run on both GPUs and MTIA without modification.
- Compilers – High-level graph compilers, kernel compilers, and lower-level backends (based on Triton, MLIR, LLVM) are optimized for MTIA, with autotuning to maximize performance.
- Kernel Authoring – Supports compiler-driven and manual kernel generation, fusion, and auto-tuning; agentic AI tools automate kernel creation.
- Communication – Hoot Collective Communications Library (HCCL) leverages built-in network chiplets for efficient, low-latency collective operations.
- Runtime and Firmware – Rust-based runtime and bare-metal firmware manage memory, scheduling, and execution across devices, delivering GPU-like performance with minimal overhead.
- vLLM Integration – MTIA plugins replace key operators like FlashAttention and fused LayerNorm, supporting graph-mode execution and batching for inference.
- Production Tools – Monitoring, profiling, and debugging tools enable full-stack observability and control across hardware, firmware, and software at scale.
MTIA: Advancing with a Portfolio Approach
Meta said its large-scale MTIA deployments have proven effective for ranking and recommendation (R&R) inference. The latest four generations — launching through 2026–2027 — are designed to extend support to GenAI inference, R&R training, and future GenAI workloads. Each generation builds on the previous one, with modular, multi-chiplet designs and co-designed software, delivering rapid performance gains while maintaining system compatibility.
Meta noted that no single chip can meet all demands, which is why it deploys a variety of MTIA chips optimized for different workloads. This portfolio approach enables faster innovation, efficient handling of diverse AI tasks, and brings the company closer to its goal of creating personal superintelligence for all users.