
Google has introduced Gemini 3.1 Flash-Lite, the company’s latest AI model that focuses on speed and cost efficiency. Google claims the model is the most cost-efficient in the Gemini 3 series, costing just $0.25 (Rs. 23 approx.) per 1M input tokens and $1.50 (Rs. 138 approx.) per 1M output tokens. It is built for high-volume developer workloads at scale, which involve high-frequency workflows and need low-latency responses.
Speaking of the raw performance of Gemini 3.1 Flash-Lite, it outperforms 2.5 Flash with a 2.5X faster Time to First Answer Token and 45% increase in output speed, according to the Artificial Analysis benchmark, while maintaining similar or better quality.
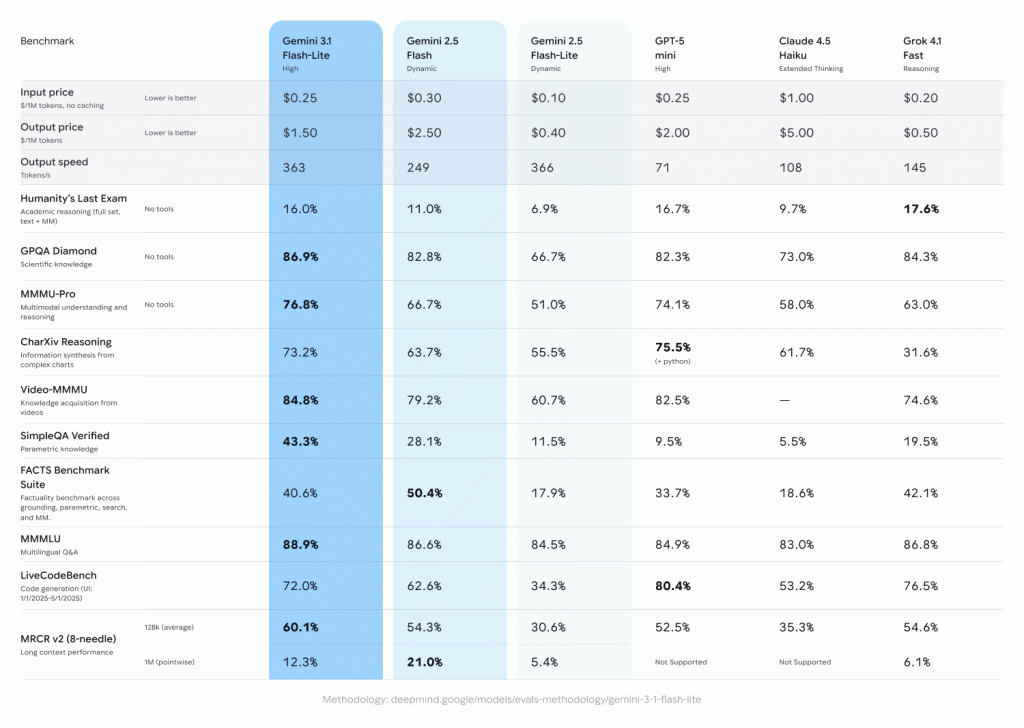
3.1 Flash-Lite achieves an impressive Elo score of 1432 on the Arena.ai Leaderboard and outperforms other models of similar tier across reasoning and multimodal understanding benchmarks, including 86.9% on GPQA Diamond and 76.8% on MMMU Pro–even surpassing larger Gemini models from prior generations like 2.5 Flash, says Google.
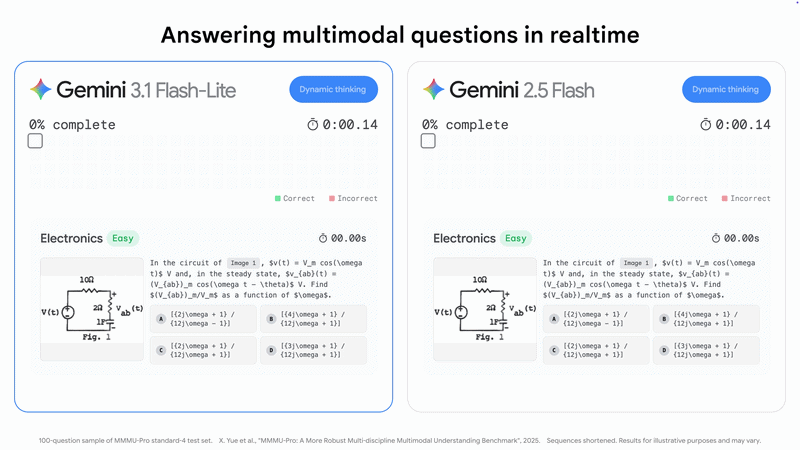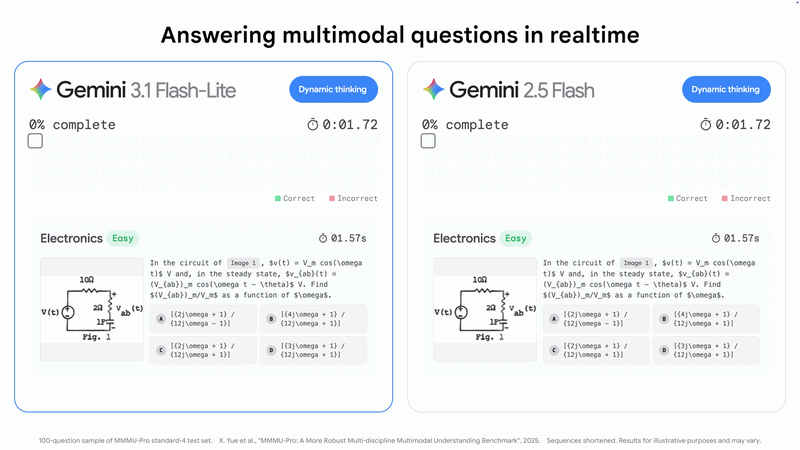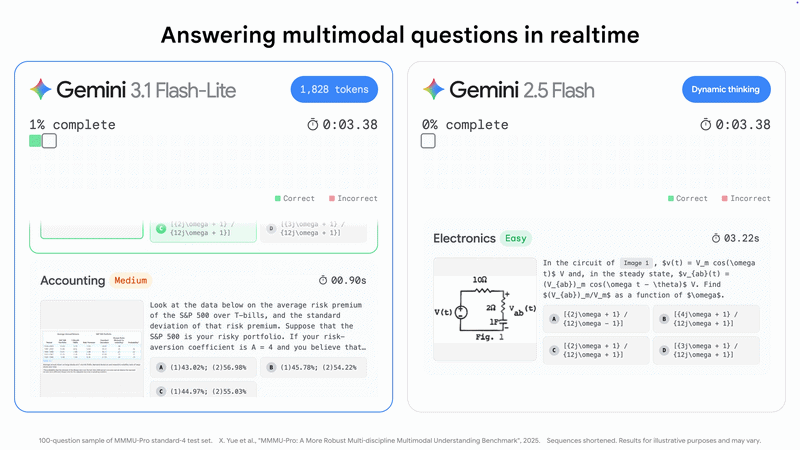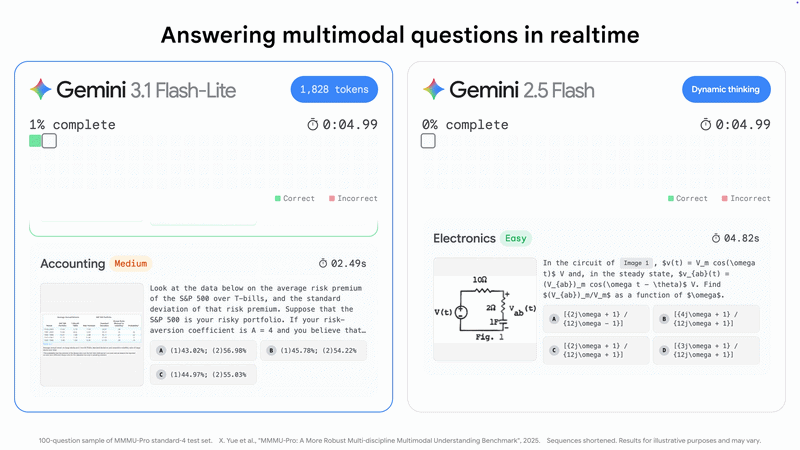
Google positions the Gemini 3.1 Flash-Lite as perfect for use cases such as high-volume translation and content moderation, classification, exploring large codebases in a fraction of time, multimodal labeling tasks at scale, and more.
It also comes standard with thinking levels in AI Studio and Vertex AI, giving developers the control and flexibility to select how much the model “thinks” for a task, which is critical for managing high-frequency workloads.
Availability
Starting today, the Gemini 3.1 Flash-Lite is rolling out in preview to developers via the Gemini API in Google AI Studio and for enterprises via Vertex AI.