Since it is a tiring job for moderators to look at every image or video posted on the enormous platform, the company is building an AI to help them out. The system it built is called Rosetta and is said to extract text from more than a billion public Facebook and Instagram images and video frames in a wide variety of languages, daily and in real time, and inputs it into a text recognition model that has been trained on classifiers to understand the context of the text and the image together.
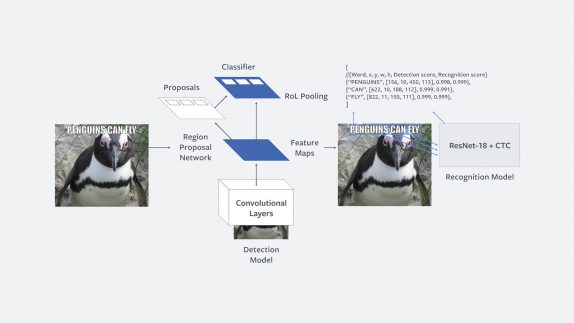
It performs text extraction on an image in two independent steps; detection and recognition. It detects rectangular regions that potentially contain text in the first step and in the second step, it performs text recognition, where, for each of the detected regions, it uses a convolutional neural network (CNN) to recognize and transcribe the word in the region.
For text detection, Facebook said that it has adopted an approach based on Faster R-CNN. In a nutshell, Faster R-CNN simultaneously performs detection and recognition by learning a CNN that can represent an image as a convolutional feature map. The whole detection system is trained jointly in a supervised, end-to-end manner. Facebook’s text detection model uses Faster R-CNN but replaces the ResNet convolutional body with a ShuffleNet-based architecture for efficiency reasons.
The company is not constraining this to English text, and currently supports different languages and encodings such as Arabic and Hindi, in a unified model. Facebook said that Rosetta has been widely adopted by various products and teams within Facebook and Instagram. Text extracted from images is being used to improve the relevance and quality of photo search, automatically identify content that violates hate-speech policy on the platform in various languages, and improve the accuracy of classification of photos in News Feed to surface more personalized content.